Zero to Hero学习笔记
Neural Networks: Zero to Hero学习笔记
1.Micrograd
1 | class Value: |
- 这是一个很简单的python类,PyTorch底层也是这样实现的吗?
- 是的,PyTorch也是通过类似的方式实现自动微分的,但它在底层是使用C++和CUDA实现的,为了提升程序的计算性能。PyTorch使用了一个叫做Autograd的系统,它通过构建计算图来跟踪操作,并在反向传播时计算梯度。
- Value类的设计思路?
- 神经网络中参数的优化依赖梯度下降,而梯度下降依赖于损失对每个参数的梯度。这一梯度的计算是通过微分的链式法则实现的,简单来讲,损失对当前变量的梯度,就等于损失对当前变量的父节点的梯度乘以父节点对当前变量的梯度。因此,我们在每个节点内部保存了该节点的所有孩子节点(self._prev),以及这些孩子节点进行的运算(self._op)以计算当前节点对孩子节点的梯度,还保存了当前节点自身的梯度(self.grad),二者相乘,便可以得到当前节点的孩子节点的梯度。但这里有一个问题:当前节点梯度的计算(可能)依赖于当前节点的兄弟节点以及当前节点的父节点,因此Value类的梯度计算方法
_backward无法计算当前节点(self)的梯度,它只能计算当前节点的孩子节点的梯度。也就是说,Value类对象的_backward属性是一个函数(方法),该函数的作用是给当前节点的孩子节点的梯度赋值(实际上是累加+=)。因此,链上的第一个节点(即损失L)的梯度是没有人给它赋值的,我们直接在backward方法中将其显式赋值为1.0。
- 为什么要进行拓扑排序?为什么不递归(如DFS,BFS)计算链上节点的梯度?
- 从数学上讲,由于梯度的累加设计,使用不带visited标记的DFS也可以实现梯度的计算。例如:
1
2
3
4def _backward(self):
for child in self._prev:
child.grad += self.grad * child._op_grad(self)
child._backward() - 但是,考虑两条路线,均从O出发,最终到达L:(1)O->X->Y->A->B->C->D->E->F->L;(2)O->X->Y->A->D->L。如果使用上述的DFS方法,会导致重复计算节点A及其之前的节点梯度,这一冗余计算是指数级的,因此我们需要使用其他方法来处理“同一节点出现在多条路径”的问题。这里我们使用拓扑排序,保证每个节点的所有父节点梯度一定先于该节点的梯度被计算,这样就在最大程度上减少了冗余计算。值得一提的是,这里的拓扑排序算法是基于DFS实现的,而不是一般的Kahn算法(维护入度=0的队列),用DFS算法可行的原因是,DFS的本质是沿着一条路径一直走到尽头,因此使用“后序遍历”(topo.append(v)在递归后面)可以实现拓扑排序的效果,且代码更简洁。
- 为什么_backward方法中是累加(+=)而不是直接赋值(=)?
- 这么做的目的很显然,从上面的例子也可以看出来。如果一个节点参与了多条路径的计算(有环),那么它的梯度应该是来自多条路径的梯度之和,如果直接赋值,那么就会覆盖之前计算的梯度,导致最终的梯度不正确。这也是为什么PyTorch中的梯度是累加的,而不是直接赋值的,因此在每次反向传播之前,通常需要将梯度清零(例如optimizer.zero_grad())。
- 为什么_backward方法中是累加(+=)而不是直接赋值(=)?
2.Transformer
- PyTorch中的buffer是什么?有什么用?
pytorch中,一个 nn.Module 通常包含两种数据:Parameters(参数) 和 Buffers(缓冲区)。然而,与Parameters不同,buffer并不是一个专门的pytorch类,它本质上是一个带标记的特殊张量,用以保存那些不需要梯度下降更新,但又是模型状态一部分的张量,例如模型的均值和方差(在BatchNorm中),或者是一些预计算的常量(例如位置编码,掩码等)。在创建一个nn.Module类时,通过
self.register_buffer('name', tensor)将该张量注册为buffer。它的主要作用有三点:自动跟随设备移动: 当你调用 model.to(‘cuda’) 时,所有注册为 buffer 的张量会和 parameter 一起自动搬运到 GPU 上。
自动序列化(保存/加载): 当你执行 torch.save(model.state_dict(), …) 时,buffer 会被包含在字典中。下次加载模型时,它们会自动恢复。
不参与梯度计算: 默认情况下,注册的 buffer 不会被 model.parameters() 返回,因此优化器不会去更新它。
| 特性 | 普通 Python 变量 (self.x) | 使用 register_buffer |
|---|---|---|
| 设备同步 | 不会自动移动。模型在 GPU,它可能还在 CPU,报错! | 自动同步。模型去哪它去哪。 |
| 保存加载 | state_dict 不含此项,模型重启后它可能变回初始值。 |
自动持久化。随模型文件一起保存。 |
| 分布式训练 | 在多卡同步时,可能导致状态不一致。 | 易于管理。PyTorch 框架知道它的存在。 |
- Transformer为什么使用残差连接?
- 这是一个相当深入的问题,实际上,残差连接在各种网络中都是一个相当通用且有效的设计思想,有很多这方面的研究,这里只简单列举几个原因:首先,随着网络层数增加,梯度在与每一层的参数相乘的过程中会逐渐变小,产生梯度消失问题,通过引入残差连接,即output=input+F(input),这使得输出的梯度为1+F’(input),即使F’(input)很小,输出的梯度也不会消失。其次,在传统模型中,随着层数不断增加,误差可能反而会变大,因此我们希望增加层数至少不会让模型变得更差,也就是新增的层数对原输出没有任何影响,即恒等映射。在这种情况下,模型会学习到F(input)=0,那么该层的输出就等于输入,这样,随着新层的加入,要么模型性能得以改善,要么性能保持不变,而不会变差,这样我们就保证了模型一定是在往更好的方向发展。最后,残差连接还可以看作是一种特征融合的方式,它允许模型在不同层次上学习不同的特征,并将它们融合在一起,这样可以提高模型的表达能力和泛化能力。
- 为什么现代transformer要颠倒add和norm的顺序?(Post-LN->Pre-LN)
- 这是一个相当有争议的问题,实际上Post-LN和Pre-LN各有优缺点,取决于具体的应用场景和需求。简单来说,Post-LN中的原输入X在LN内部,参与LN梯度的计算,可能导致梯度模长过大,在训练和预热阶段模型容易发散;而Pre-LN中的原输入X在LN外部,不参与LN梯度的计算,数值更稳定,训练和预热阶段不容易发散,实际上,Pre-LN在所有层之间为输入X构建了一条不受阻碍的线性通道。但是,经过精细的训练,Post-LN的性能上限略优于Pre-LN。Post-LN敏感但性能好,Pre-LN稳定但性能略逊。
- 现在训练出的transformer模型仅仅能够预测下一个token,它还不能实现像chat-gpt那样回答问题,如何进一步实现?
- 训练一个像chat-gpt那样的大语言模型基本上包含两个阶段:预训练和微调。我们目前所做的仅仅是它的预训练阶段,模型能根据上下文自动续写文本。但为了让模型能够适应特定的“问答”任务,我们还需要对它进行微调,简单来讲,微调就是在针对特定下游任务的数据集上对原始模型做尽可能少的改动(比如增加一个稠密层)并在这个数据集上重新训练模型,模型原来的参数会被微调,新加入层的参数则从头开始训练。gpt的微调更复杂一点,它包含三个阶段:监督微调(SFT),奖励模型训练(RMT)和强化学习(RL)。SFT阶段,使用人类标注的问答数据集对模型进行微调,使其能够更好地理解和生成自然语言。RMT阶段,训练一个奖励模型来评估模型生成的回答的质量,这个奖励模型通常也是一个神经网络,它会根据人类的反馈来评估回答的好坏。RL阶段,使用强化学习算法(如PPO)来进一步优化模型,使其在生成回答时能够最大化奖励模型给出的评分,从而提高回答的质量和相关性。这里可以参考GPT微调讲解视频(在P8)。
3.Tokenizer
tokenize,或词元化,就是将一个序列文本分割成tokens的过程,形式上讲,tokenizer是一个函数,它接受一个字符串输入,输出一个整数索引列表(token ids)。这里推荐一个可视化网站。一般来说,词表(vocab)越大,语料序列(corpus)越短,tokenizer的效率就越高,但同时也会增加模型的参数量和计算复杂度,反之亦然,因此存在一个平衡点/甜点/纳什均衡。
- UTF-8编码是什么?
- UTF-8是一种可变长度的字符编码方式,它使用1到4个字节来表示一个Unicode字符。对于ASCII字符,使用单字节编码,对于非ASCII字符,使用多字节编码。
- 为什么BPE算法要在原序列的UTF-8编码的基础上进行分词而不是直接在原序列的每个Unicode字符上进行分词?/为什么BPE使用基于字节的拆分(例如将’안’拆分为b’\xec’,b’\x95’,b’\x88’即[236, 149, 136])而不是基于字符的拆分(例如将’teacher’拆分为’teach’,’er’)?
- 现代BPE算法大多采用基于字节的拆分(BBPE)。Unicode包含超过14万个字符,直接在Unicode字符上进行分词会导致词表过大,如果进行BPE算法,还会导致词表进一步增大,模型复杂度过高,此外,如果训练语料里没有出现过某个罕见汉字或特殊的 Emoji,模型在推理时遇到它就会彻底“卡死”,因为它不在初始词表里;而基于UTF-8编码,任何Unicode字符都可以被表示为若干个取值为0-255的字节,因此无论语料库多么复杂,词表初始大小均为256,从 256 个“原子”开始合并,可以让模型用极小的代价覆盖全球所有语言,而不会因为初始字符集太大而导致 Embedding 层占用过多空间。并且由于所有 Unicode 字符最终都能拆解成 256 个基础字节中的某几个,那么理论上任何新字符、新单词都可以被拆解回字节层级进行编码,模型即使没见过这个字,也能通过组成这个字的字节片段来尝试理解或处理它。TikToken就是一个基于字节的BPE算法实现的Tokenizer,而SentencePiece则是一个基于字符(当然,也可以设置为基于字节,或二者混合)的BPE算法实现的Tokenizer。
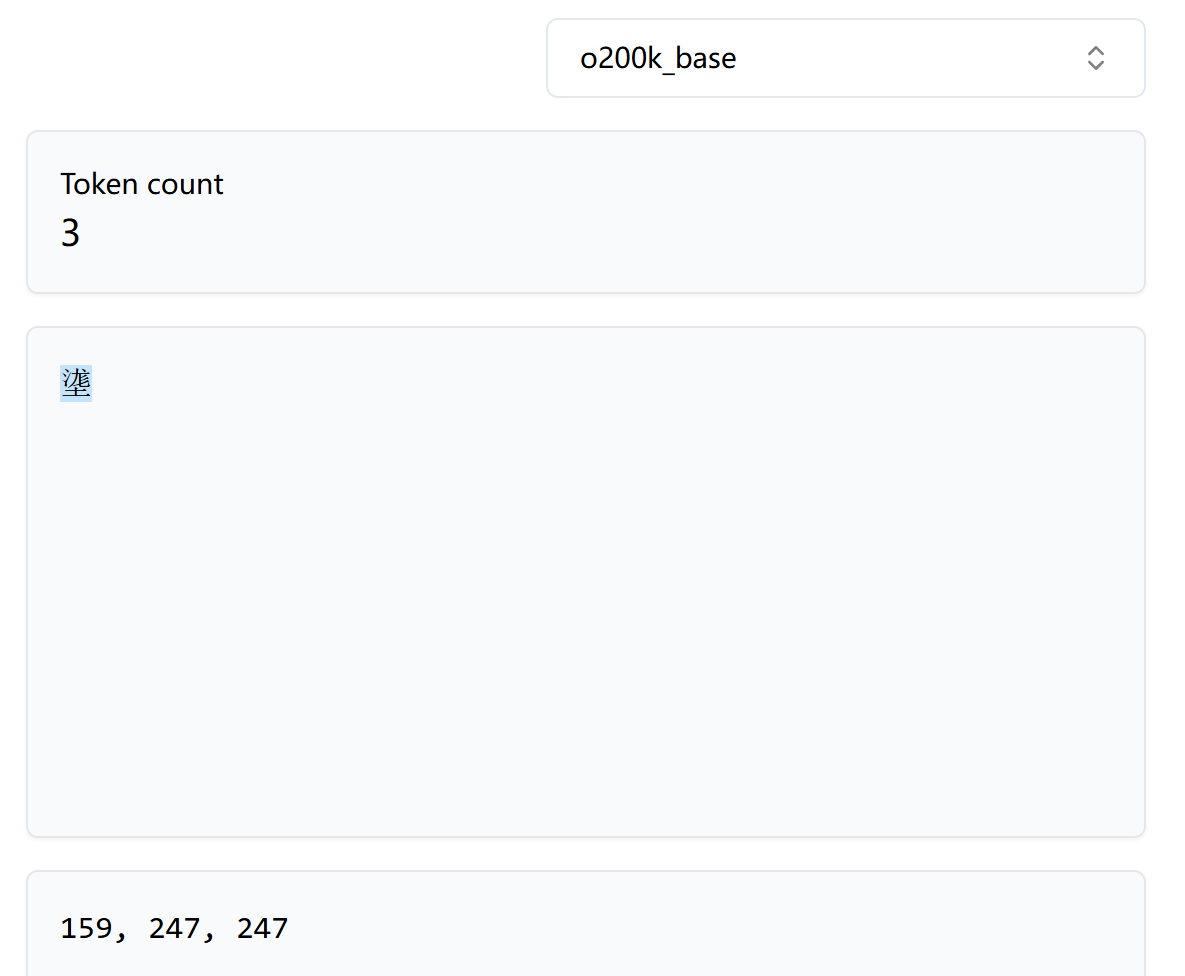
对于罕见字“㙙”,分词器拆分出了三个token,实际上,由于这三个token均小于256,因此它们就是该字符的原始UTF-8编码字节:
但可以看到,对于常用词,在Tokenize的过程中,每个字符(甚至多个字符)的字节直接被合并为了一个token: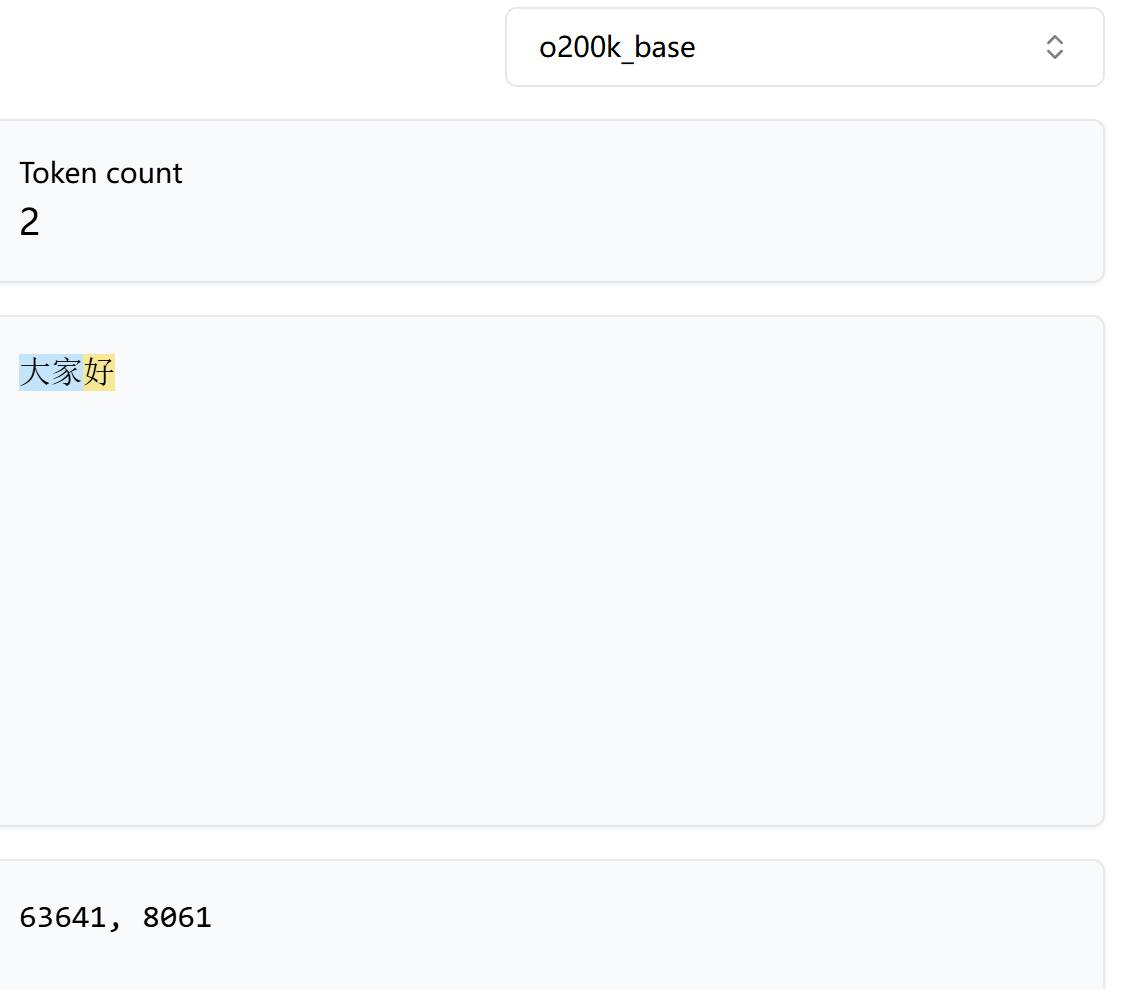
- Tokenizer和LLM的关系?数据流动方式?
- 这里的Tokenizer是d2l中vocab对象的超集,它们的功能大体上一致,但Tokenizer包含预处理和算法部分。Tokenizer和LLM是完全独立的对象,它们分别有自己的训练过程,是完全解耦的。一般来说,输入序列在被LLM处理时,要经过以下步骤:原始Unicode字符串->UTF-8字节序列(1个字符对应若干个0-255的整数)->通过分词器(Tokenizer)转换为tokens(整数索引列表)->通过Embedding模型转换为向量序列->输入LLM进行处理->LLM输出各个tokens的预测logits->通过Softmax转换为概率分布->通过采样或贪心算法选择下一个token->Tokenizer将选中的token转换为UTF-8字节序列->将字节序列转换为Unicode字符串->输出结果。

- 序列中的一些特殊符号(比如用<>或[]包裹)是干嘛的?
- 在实际训练Tokenizer的过程中,通常会人为的向原序列中添加一些特殊的标记,例如[CLS]、[SEP]、[PAD]等(不同分词器的标记可能不同),这些标记在训练过程中会被当做普通的token进行处理,但它们在模型推理时具有特殊的意义,例如[CLS]通常用于表示整个输入序列的语义信息,常用于分类任务;[SEP]用于分隔不同的句子或段落;[PAD]用于填充序列,使得所有输入序列具有相同的长度,这些特殊标记的引入可以帮助模型更好地理解输入数据的结构和语义,从而提升模型的性能。
- SentencePiece可以设置为基于字符分词,那么它是怎么处理未知字符的?
- SentencePiece在基于字符分词的模式下会将输入文本拆分成一个个Unicode字符进行处理。对于未知字符,SentencePiece使用特殊字符
表示,此外,在特定设置下,其会将未知字符退回到UTF-8字节级别进行处理,这样就保证了模型在推理阶段能够处理任何输入文本。
- 在BBPE中,由于每个token都是一至多个连续的字节组合,那么会不会出现将两个来自不同字符或者毫不相干的字节合并的情况?怎么解决?
- 理论上讲,确实会出现这种情况,但由于BBPE的设计与一些人为干预的手段,出现这种错误的可能性很小。首先,如果一个 Token 包含了“字符 A 的一部分 + 字符 B 的一部分”,那么由于BBPE的设计思路是高频token合并,因此字符A和字符B应该本就具有很强的关联性,它们不太可能单独出现(例如‘尴’和‘尬’),因此这个“混合token”大概率会被放到正确的上下文中进行解码。其次,确实有可能出现一些毫不相干的字节被合并成一个token,例如上一句话的句号与下一句话的首字母连在了一起,对于这种情况,现代 BBPE增加了人为的限制规则,比如,在合并字节之前,Tiktoken 或 GPT 的分词器会先用 正则表达式 对文本进行“预切分”,规定空格、标点符号、数字和字母之间不能跨界合并,这样就保证了 BPE 的合并主要发生在同一个单词内部,或者同一类字符内部,大大减少了“跨字符乱合”导致的语义混乱。总的来说,BBPE能通过多次迭代,把这些跨越了“字符边界”的字节精准地打包成一个 Token,从而提高压缩效率。此外,UTF-8编码的自同步特性也保证了它可以从任何位置开始,找到每个字符的字节开始和结束位置,这样就算出现了跨字符的合并,也不会导致解码错误。
- SolidGoldMagikarp是什么?
- 由于训练分词器和LLM所用的数据集不同,因此在分词器数据集中频繁出现以至于被合并成一个token的词语,在LLM数据集中可能从来没出现过,导致该token的向量仍然保持随机初始化的状态,模型在对该token进行前向传播时也会表现出随机的,无法预测的行为。SolidGoldMagikarp就属于这类token。