ViT论文精读-学习笔记
原论文链接:https://arxiv.org/abs/2010.11929
原视频链接:https://www.bilibili.com/video/BV15P4y137jb
CV常见任务对比
| 任务 | 目标 | 结果形式 | 是否区分个体 | 精细度 |
|---|---|---|---|---|
| 图像分类 | 识别类别 | 标签 (Label) | 否 | 最低(全局) |
| 目标检测 | 定位+识别 | 矩形框 (Box) | 是 | 中等(区域) |
| 语义分割 | 像素分类 | 类别掩码 (Mask) | 否 | 高(像素) |
| 实例分割 | 个体像素分类 | 实例掩码 (Mask) | 是 | 最高(像素) |
前言
传统的计算机视觉任务通常使用卷积神经网络(CNN)来处理图像数据。然而,近年来,Transformer架构在自然语言处理(NLP)领域取得了巨大成功,引起了研究人员的兴趣,尝试将其应用于计算机视觉任务。Vision Transformer(ViT)是其中一个重要的工作,它将Transformer应用于图像分类任务,通过适当的数据预处理,ViT可以取得与传统CNN相媲美甚至更好的性能。此外,在一些特殊的极端情况下,ViT可以处理普通CNN无法解决的问题,例如图像遮挡,纹理去除,加入对抗性斑块,图像重组等。
ViT论文精读
- 将Transformer应用于视觉任务有什么难处?如何解决?
- 我们知道,Transformer的核心功能是处理序列数据,形状为(batch_size,seq_steps)或(batch_size,seq_steps,embedding_dim)。Transformer中最重要的自注意力本质上是序列中的每一个元素与所有其他元素进行交互(加权和)的过程,因此它是一个O(n^2)的操作。对于文本序列,我们可以将序列长度设为几百至一千,这在计算上是可行的。然而,对于图像数据,尤其是高分辨率图像,直接将图片拉直,每个像素作为一个序列元素会导致序列长度过长(224*224=50176),从而使得计算成本变得不可接受。
- ViT通过将图像划分为固定大小的非重叠块(patches)来解决这个问题,例如,如果在224x224的图像上使用16x16的块,那么序列长度将变为(224/16)^2=196。每个块被视为一个序列元素,并通过线性变换映射到一个固定维度的嵌入空间中。这种方法大大减少了序列长度,使得Transformer能够有效地处理图像数据。ViT的架构是相当简单的,主要由以下几个部分组成,实际上就是图像分块+标准Transformer编码器:
- Patch Embedding:将图像划分为固定大小的块,并将每个块展平后通过线性变换映射到一个固定维度的嵌入空间中。
- Positional Encoding:由于Transformer没有内置的位置信息,因此需要添加位置编码来保留图像块之间的空间关系。
- Transformer Encoder:由多个Transformer层组成,每层包含多头自注意力机制和前馈神经网络。
- Classification Head:在Transformer编码器的输出上添加一个分类头,用于图像分类任务。
- 值得注意的是,ViT的性能在很大程度上依赖于训练数据的规模和质量。在小规模数据上,由于ViT缺乏CNN的归纳偏置(locality和translation invariance),其性能可能不如CNN。然而,在大规模数据上,ViT可以通过学习更丰富的特征表示来取得更好的性能。因此,ViT通常在大规模数据集上进行预训练,并通过微调接入下游任务。
- 虽然在该论文中ViT主要用作图像分类任务,但后续的其他工作已经证明,ViT架构也可以应用于其他计算机视觉任务,如目标检测、语义分割等。在这些任务中,ViT可能需要进行一些修改,例如引入局部注意力机制或结合CNN的特征提取能力,以提高性能。
ViT的主体架构
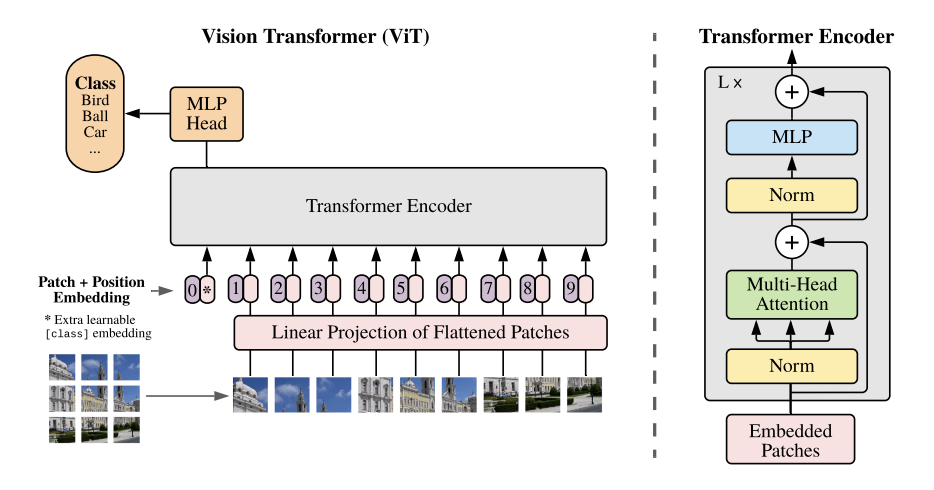
数据处理流程:1
2
3
4
5
6输入图像(224,224,3)
-[分块]-> (14,14,16,16,3)
-[通过768->768的linear进行patch embedding/patch projection]-> (196,768) (224x224/16x16=196, 16x16x3=768)
-[positional encoding与用于分类的虚拟头token<cls>]-> (197,768)
-[Transformer编码器]-> (197,768)
-[<cls>token进入768->num_classes的分类头]-> 分类结果
除了加入特殊的全局语义token
<cls>,最终将<cls>连到线性分类头以产生分类结果,也可以不加入<cls>,直接将Transformer编码器输出的每个token进行全局平均池化后输入分类头。关于位置编码:经典的Transformer使用1D的位置编码,假如编码的目标维度为d,那么这d个值全部用来表示原token在一维序列中的位置;而2D的位置编码,假如编码目标维度为d,那么这d个值的一半用来表示原patch在二维图像中的行位置,另一半用来表示原patch(token)在二维图像中的列位置,然后把行表示和列表示拼接起来形成d维位置编码;相对位置编码则是通过计算patch之间的相对位置关系来生成位置编码,而不是直接使用绝对位置。实际上,在ViT中,这三种位置编码方式的性能差异不大。
关于归纳偏置:ViT中的MLP是具有CNN的locality和translation invariance的,但是Attention部分缺乏这些归纳偏置,它是全局的。图片的2D信息ViT几乎没有使用(仅在patch encoding使用了),因此ViT在小规模数据上性能不如CNN;但是在大规模数据上,ViT通过注意力机制的优良特性,能够学习更丰富的特征表示来取得更好的性能。从这个角度看,ViT的潜力是巨大的。这也引出了混合的ViT架构,即先使用CNN提取局部特征,然后将这些特征输入到Transformer中进行全局建模,以结合两者的优势,该混合模型在某些场景下表现优于CNN和ViT。
关于微调ViT:使用不同大小的图片会导致不同数量的patches,从而导致Transformer编码器输入的序列长度不同。为了适应不同大小的图片,ViT通常会在预训练阶段使用固定大小的图片进行训练,然后在微调阶段根据需要调整输入图片的大小。对于较大的图片,可以通过增加patch的大小来减少序列长度;对于较小的图片,可以通过减少patch的大小来增加序列长度。此外,如果patches数量发生改变,先前的位置编码也不再适用,可以使用插值方法来调整位置编码,以适应新的输入尺寸。
关于数据集选择和训练:ViT在大规模数据集上表现更好,只有在大规模数据集上进行预训练,才能充分发挥其优势。因此通常在ImageNet-21k或JFT-300M等大规模数据集上进行预训练,然后在较小的数据集(如ImageNet-1k)上进行微调。此外,ViT的训练通常需要较长的时间和更多的计算资源,因此在实际应用中,研究人员可能会选择使用预训练的ViT模型,并通过微调来适应特定的任务和数据集。
后记
ViT的意义不仅仅是在图像分类任务上提升了几个百分点,而是展示了Transformer架构在计算机视觉领域的潜力和适用性,它构建了NLP与CV交叉的新桥梁。同时,它也表明了Transformer架构的通用性与巨大潜力,推动了后续涉及更多领域的多模态大模型的发展。总之,ViT是一个重要的里程碑,它不仅在技术上取得了突破,还为未来的研究和应用开辟了新的方向。