李宏毅-扩散模型-学习笔记
原视频链接:https://www.bilibili.com/video/BV14c411J7f2
原论文链接:https://arxiv.org/abs/2006.11239
1. DDPM
- 什么是扩散模型(Diffusion Model)?
- 扩散模型是一类生成模型,通过模拟数据逐渐被噪声破坏的过程来学习数据分布。扩散模型的核心思想是定义一个正向扩散过程,将数据逐渐添加噪声,直到变成纯噪声;然后定义一个反向扩散过程,学习如何从纯噪声逐步去除噪声,最终恢复出原始数据。通过训练一个神经网络来拟合反向扩散过程,扩散模型能够生成高质量的样本。
- 什么是扩散模型(Diffusion Model)?
- 扩散模型的基本原理是什么?
- 扩散模型的输入是一张从某种分布(如高斯分布)采样的纯噪声图像,该图像的尺寸与想要生成的目标图像一致。模型包含多个Denoise块,每个块接受两个输入:一个含有噪声的图像,以及该图像的噪声严重程度(或当前时间步),靠近输入的时间步较大,而靠近输出的时间步较小。图像在经过这些Denoise块时,噪声逐渐被去除,最终输出一张清晰的图像。每个Denoise块的核心是一个用来预测的神经网络,负责根据当前输入图像和时间步信息预测噪声的分布,然后从输入的图像中减去预测的噪声,就得到一个更清晰的图像。以上是扩散模型的反向扩散过程,类似于模型的预测/生成过程。
- 而扩散模型的训练过程,即正向扩散过程,是通过逐步向原始图像添加噪声来生成训练数据的。具体来说,给定一个原始图像,模型会在多个时间步上逐渐添加噪声,直到图像变成纯噪声。每个时间步对应一个特定的噪声水平,这个添加的噪声就作为训练标签,模型通过最小化预测的噪声与实际添加的噪声之间的差异,学习到如何有效地去除噪声,从而在生成阶段能够从纯噪声开始逐步生成高质量的图像。
- 扩散模型的基本原理是什么?
- 如何根据文字描述生成图像?
- 简单来说,与第2点介绍的模型原理相比,在生成阶段,只需要在每个Denoise块(实际上是其内部的预测神经网络)的输入中加上一个额外的条件输入(Conditioning Input),这个输入就是文本描述的特征向量(这个特征向量可以通过一个预训练的文本编码器(如BERT或CLIP)从文本描述中提取出来);而在训练阶段,样本的features变为加入噪声后的图片,时间步与文本向量,label是加入的噪声, 模型同样需要在每个Denoise块的输入中加入这个条件输入,以便模型能够学习到如何根据文本描述预测噪声。通过这种方式,扩散模型能够根据文本描述生成与之相关的图像。
- 如何根据文字描述生成图像?
2. Stable Diffusion
- Stable Diffusion是什么?
- Stable Diffusion是一种基于扩散模型的文本到图像生成方法,旨在通过引入稳定的训练过程和高效的架构设计来生成高质量的图像。Stable Diffusion通过改进传统扩散模型的训练策略和网络结构,使得模型在生成过程中更加稳定,并且能够更好地捕捉文本描述与图像之间的关系,从而生成更符合文本描述的图像。
- Stable Diffusion是什么?
FID(Fréchet Inception Distance)是评估生成模型性能的一种常用指标,主要用于衡量生成图像与真实图像之间的相似度。FID通过计算生成图像和真实图像在某个特征空间(通常是Inception网络的某一层输出)的均值和协方差来评估两者之间的距离。具体来说,FID计算生成图像和真实图像的特征分布之间的Fréchet距离,数值越小表示生成图像与真实图像越相似。因此,FID是评估生成模型质量的重要指标之一,尤其是在文本到图像生成任务中。
CLIP(Contrastive Language-Image Pre-training)是一种预训练模型,旨在通过对比学习的方式同时处理文本和图像数据。CLIP通过在大规模的文本-图像对上进行训练,使得模型能够学习到文本和图像之间的语义关系。CLIP的核心思想是将文本和图像映射到同一个特征空间中,使得相关的文本和图像在该空间中距离较近,而不相关的文本和图像距离较远。CLIP在许多任务中表现出色,尤其是在零样本学习(zero-shot learning)和跨模态检索(cross-modal retrieval)等领域,成为了文本到图像生成任务中的重要工具之一。
Stable Diffusion的基本原理是什么?
Stable Diffusion的整体架构为:一个文字(或其他形式的输入)编码器,该编码器将输入转换为特征向量;一个生成模型,该模型接受噪声图像和输入文字的特征向量作为输入,输出一个压缩的特征图,且通常是一个基于U-Net Predictor的扩散模型;一个解码器,该解码器将生成模型输出的特征图转换为最终的图像。这三个部分共同构成了Stable Diffusion的生成流程,并且是独立训练的。
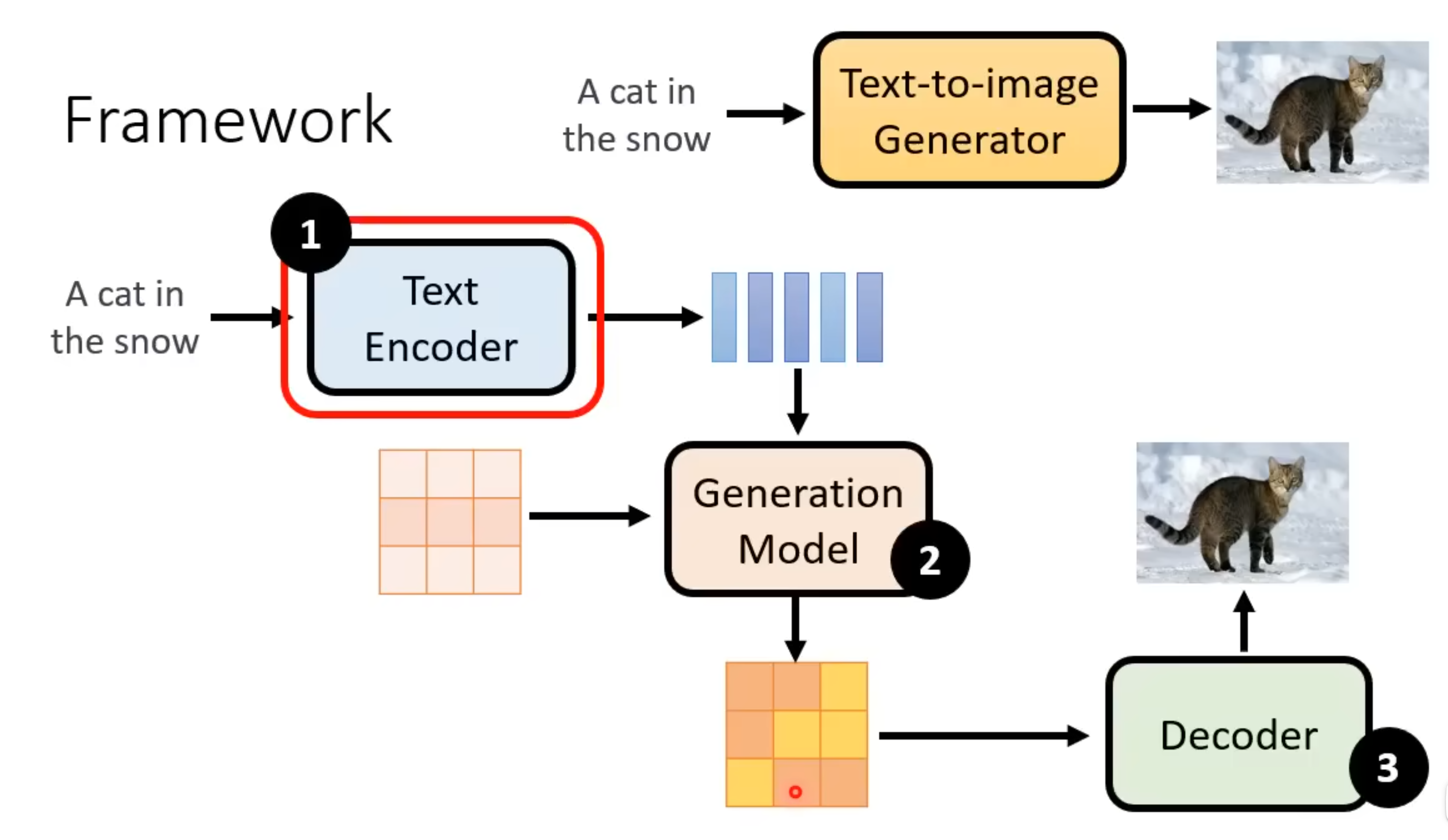
编码器:Stable Diffusion通常使用一个预训练的文本编码器(如CLIP)来将输入的文本描述转换为特征向量。这个特征向量捕捉了文本描述中的语义信息,为生成模型提供了条件输入。
- 解码器:Stable Diffusion的解码器通常是一个基于U-Net架构的神经网络,负责将生成模型输出的压缩特征图转换为最终的图像。对于解码器的训练,分两种情况:如果生成模型生成的是目标图片的压缩图(内容与目标图片一致,只是尺寸更小),则直接提供原图与压缩后的图片分别作为标签和特征就可以训练解码器;如果生成模型生成的是特征图(只是目标图像的某种latent representation,与目标图像看起来“不像”),则需要先训练一个单独的编码器,将目标图像编码成特征图,然后再使用这个编码器的输入作为解码器的训练标签。
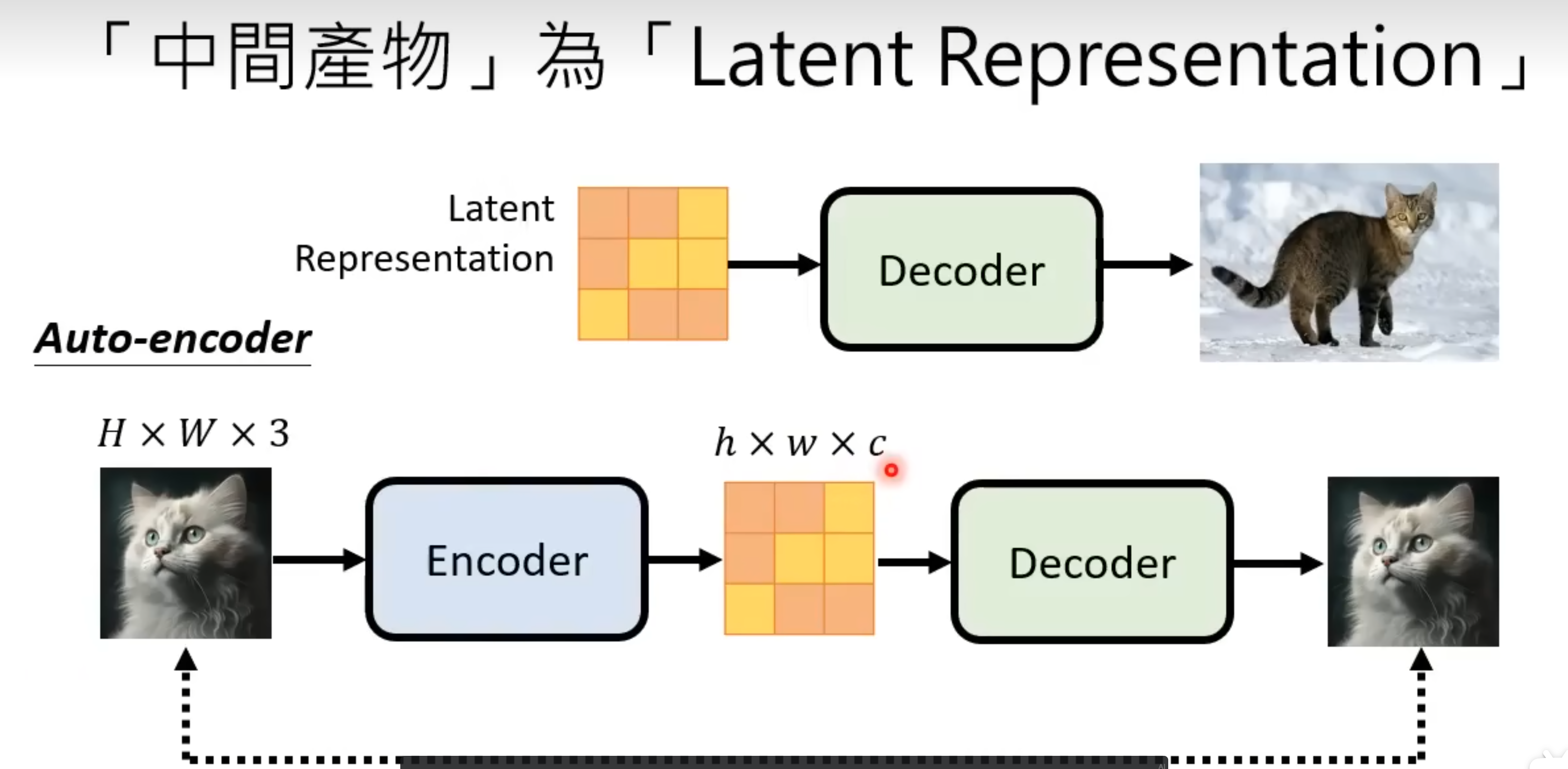
- 生成模型:Stable Diffusion的生成模型通常是一个基于U-Net架构的扩散模型,负责从输入的噪声图像和文本特征向量中生成一个压缩图/特征图。如果输出是压缩图,那么生成模型的训练标签就是目标图像的压缩版本,训练过程同DDPM;如果输出是特征图,那么生成模型的训练标签就是目标图像经过编码器处理后的特征图,通过在每一步给这个特征图加入噪声,让模型学习如何预测噪声,生成模型能够逐步生成与文本描述相关的图像特征,最终通过解码器转换为图像。无论生成模型的输出是压缩图还是特征图,训练过程和生成过程都与DDPM类似,只是在输入中加入了文本特征向量作为条件输入,并且输出分别是压缩图或特征图。
3. DDPM的训练算法

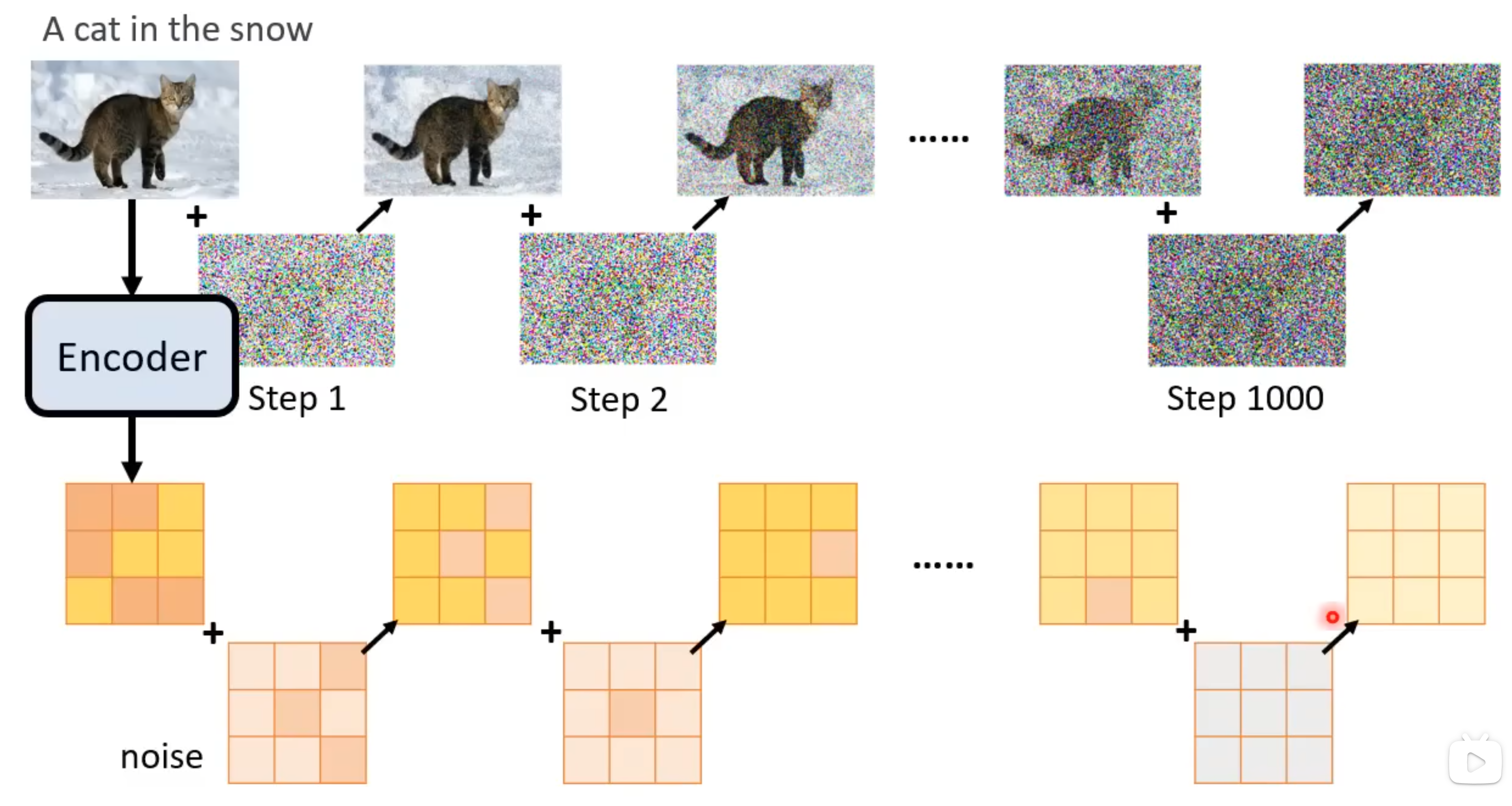
实际上,在训练时,并不是逐渐递增时间步t的值,每次递增都在图像上增加一点噪声,而是直接从均匀分布中随机采样一个时间步t的值,这个t的取值决定了向图像中加入噪声的严重程度,t越大,加入的噪声越多;t越小,加入的噪声越少。然后把时间步t和混入噪声的图片一起输入Denoise块的预测器中,预测器的目标是预测出当前加入的噪声,然后以预测的噪声与实际加入的噪声之间的差异作为损失函数进行梯度下降,从而使模型学会如何根据当前的图像和时间步预测混入的噪声。
在逻辑上,正向扩散应该是迭代式的,即从原始图像开始,逐步添加噪声,直到变成纯噪声;然而在实际训练时,通常是一步到位(即上面所说的),这是因为由于每次噪声都是从标准正态分布采样,因此多次采样的叠加结果就等价于一次采样的结果(因为正态分布的叠加仍然是正态分布),此时这个“一次采样”的系数可以通过迭代采样系数的累乘得到,因此出于效率和简化计算的考虑,训练时直接从均匀分布中随机采样一个时间步t的值,并根据这个t的值一次性地向图像中加入相应程度的噪声。

4. DDPM的生成算法
- 任何一个生成式模型(无论带不带条件输入)在生成阶段都是从纯噪声开始,逐步还原图像,最终得到一个输出图像,而模型的目标,就是让输出图像的分布尽可能接近真实的图像分布。因此这里采用MLE或最小化KL散度。
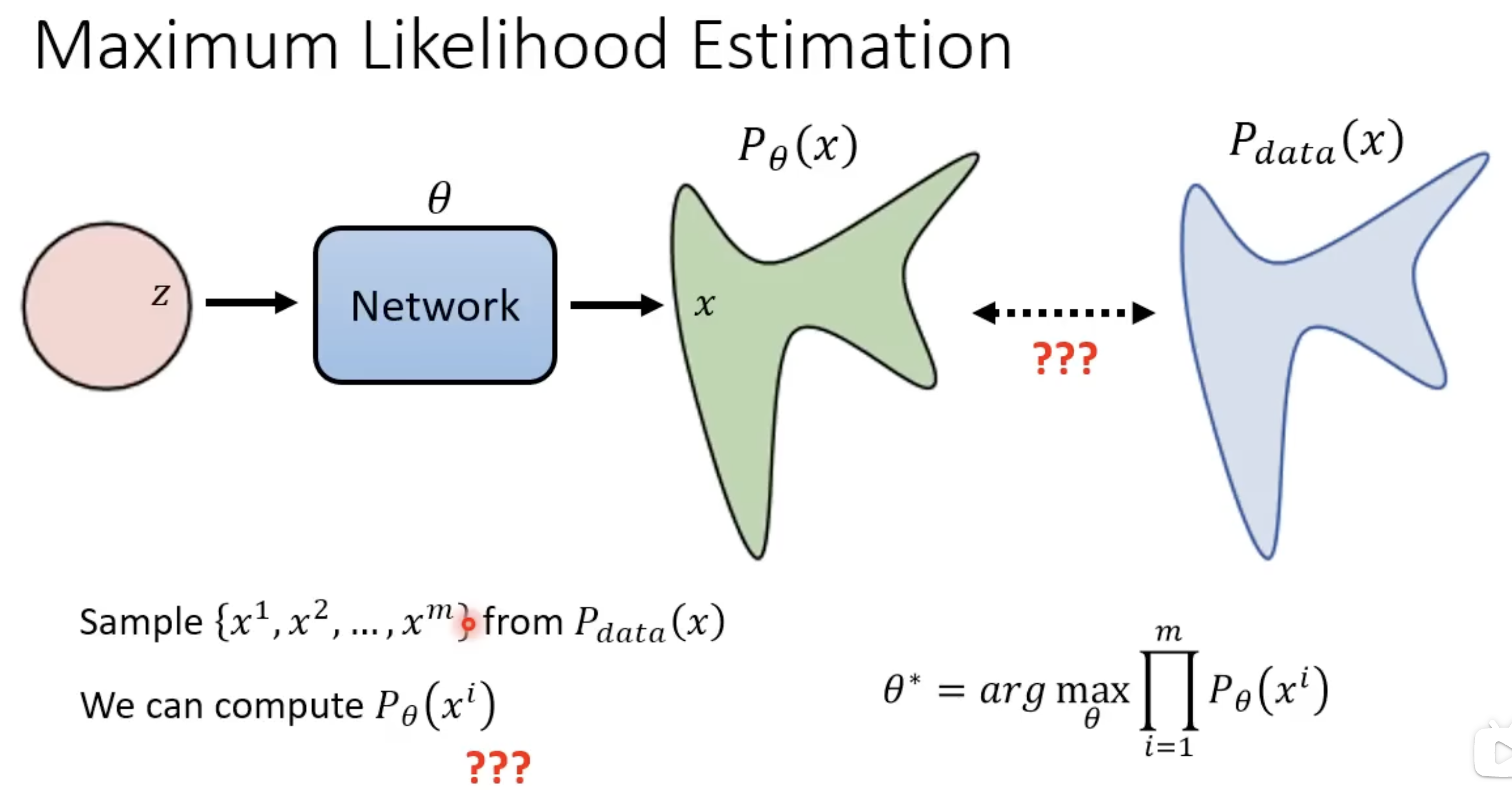

- 任何一个生成式模型(无论带不带条件输入)在生成阶段都是从纯噪声开始,逐步还原图像,最终得到一个输出图像,而模型的目标,就是让输出图像的分布尽可能接近真实的图像分布。因此这里采用MLE或最小化KL散度。
- VAE的Lower Bound:这里的概率推导有点令人匪夷所思…总之是为了找到一个 $log p_\theta(x)$ 的下界(ELBO),从而通过最大化这个下界来训练模型。

- VAE的Lower Bound:这里的概率推导有点令人匪夷所思…总之是为了找到一个 $log p_\theta(x)$ 的下界(ELBO),从而通过最大化这个下界来训练模型。
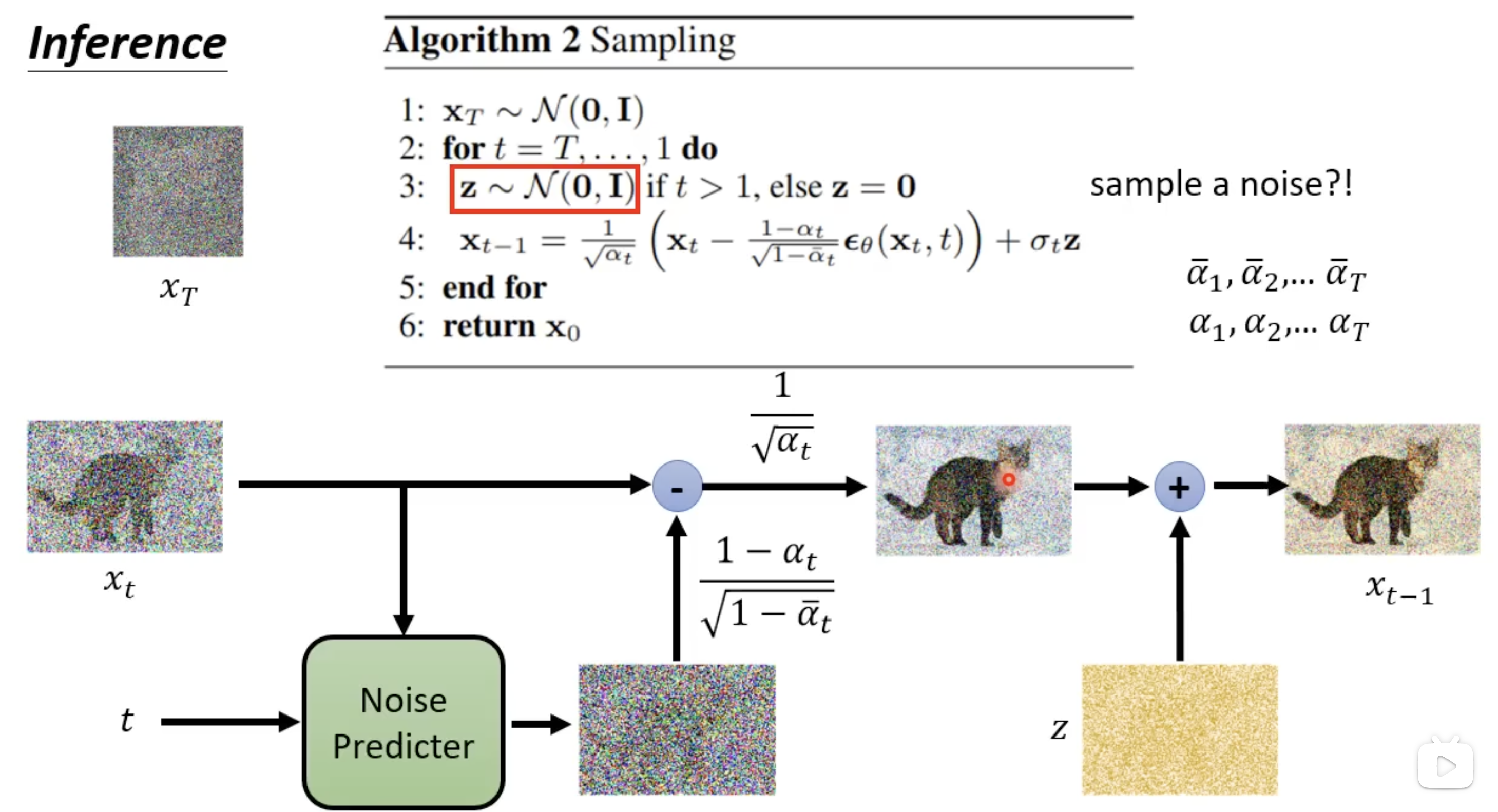
- 将同样的思想应用到DDPM,实际上Denoise块的输出就是一个条件概率分布,表示在当前时间步t和输入图像的条件下,预测的下一步图像分布,假定图像服从Gaussian分布,那么Denoise块就给出了这个Gaussian分布的均值和方差(或者直接给出噪声的预测)。假如初始图像(纯噪声)为 $x_T$ ,最终生成的图像为 $x_0$ ,那么在每一步t,模型都要根据当前的图像 $x_t$ 和时间步t来预测下一个图像 $x_{t-1}$ 的分布,且有
- DDPM的Lower Bound:推导过程类似VAE

- 生成算法第4步中的第一项(即 $\frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \right)$ 是怎么来的?
- 实际上,这一项是为了满足DDPM的优化目标(即maximize那个期望项)而得到的,这里省略了一些相当复杂的数学推导,详细请看视频或原论文。
- 生成算法第4步中的第二项(即 $\sigma_t \mathbf{z}$)是怎么来的?
- 这一项是为了引入随机性,使得生成的图像具有多样性。$\sigma_t$ 是一个与时间步t相关的噪声强度参数,$\mathbf{z}$ 是从标准正态分布采样的随机噪声向量。通过在每一步生成过程中加入这个随机项,模型能够生成不同的图像,即使输入的初始噪声相同,也能通过不同的随机采样得到多样化的输出。实际上,如果没有这一项,模型容易进入某种重复性的生成模式,导致生成的图像完全难以辨别,或过于单一(如纯色)。
5. Stable Diffusion在其它领域的应用
- 对于连续信息(如数据,音频),可以直接使用Stable Diffusion进行生成
- 对于离散信息(如文本),由于扩散模型是基于概率分布,是连续的,因此可以先将离散信息编码成连续的特征向量(如通过预训练的文本编码器),然后基于特征向量进行生成,最后再通过一个解码器将生成的特征向量转换回离散信息(如文本)。也可以不采用Gaussian分布,而是使用离散分布,这样就自然能够处理离散信息。
6. 后记
扩散模型在图像生成方面表现出色,并且可以迁移到其它连续或离散信息的生成中。它通过多次迭代,逐步去噪(这实际上类似于一个多次自回归的过程),解决了传统的单次自回归模型的诸多问题,例如错误累积,生成内容单一等,同时也提供了一种基于概率分布的多轮自回归的生成模型范式,而不是传统的“一步到位”,因此具有重要的意义和广泛的应用前景。