变分自编码器VAE
本文旨在用最简短的篇幅,描述VAE的核心思想与设计动机,仅作为日后回顾VAE的一个记忆锚点,具体公式和代码请参考其它资料。此外,本文尽可能省略一切数学推导
参考:https://zhuanlan.zhihu.com/p/574208925
https://www.bilibili.com/video/BV1wx421k74m
首先,无论是GAN,还是DDPM,还是VAE,它们在应用层面的目的都是一样的:生成一张“真实”的图像。仅仅是这个目的的话,其实很简单,只需让这个模型无论如何都输出一张相同的来自真实世界的照片就行了。但这显然不是我们想要的,因此,生成模型最重要的部分就是其输入,以及如何表示这个输入,我们想要的是,不同的输入可以产生不同的输出图像,相似的输入可以产生相似的图像,具有特殊含义(例如输入一段有特定含义的文字)的输入可以产生某些特定的图像。在DDPM模型中,我们本质上是将输入映射到了一个与图像大小相同的空间中(纯噪声),然后再从这个空间采样,得到想要的图像,但这样有个严重的问题:输入图像一般很大(如1024x1024x3),那么我们得到的输入表示也在一个1024x1024x3的空间中,这样的表示是非常巨大的,在计算上可能不可行。因此,自编码器(AE)就提出了这样的思想:我们可以先通过编码器把输入图像映射到一个较小的空间(即latent space)得到一个低维的表示(有人会问,这样的降维会不会丢失信息?答案是肯定的,但是实验证明,在AE/VAE中,模型损失的一般是“感知信息”而不是“语义信息”,感知信息比较容易从周边推测出来,因此它的损失影响不大,而语义信息则可以看作对原图像的一种高度概括,它包含着对图像来说真正重要的信息,因此我们希望减少其损失),然后再通过解码器把这个低维表示映射回图像空间,优化目标就是缩小解码器生成的图像与原输入图像间的差距。这样,只要我们在latent space中采样一个点,就可以通过解码器得到一张图像了。
但是,AE模型有一个致命的缺陷:过拟合。AE的编码器,潜在表示,解码器全都是确定性的,只要网络够复杂,数据够多,解码器完全可以“记住”每一张输入图像和它的潜在表示的样子,这样就将损失降到了0。但在我们真正使用解码器生成图像的时候,我们会在潜在空间中随机采样一个潜在表示,然后把这个潜在表示传给解码器,假如这个潜在表示碰巧在训练集里出现过,那么解码器会生成与训练集中输入图像一模一样的图像,这就缺乏了创新性;假如这个潜在表示没有出现在训练集里,由于该模型是极度过拟合的,因此解码器对该潜在表示的行为几乎是完全不可预测的,很有可能生成一堆乱码。因此,AE这种确定性的潜在表示显然是不合适的,而VAE正是为了解决这个问题而提出的。
VAE实际上可以看作是一种正则化的AE。VAE的思想是这样的:既然编码器输出潜在空间的一个点会导致上述问题,那么我不再输出一个点,而是输出一个分布(一般是高斯分布,原因后面会讲),不就可以大大增加随机性和泛化能力了么。实际上,输出一个概率分布是做不到的,编码器输出的是这个概率分布的参数(高斯分布的期望和方差)。那么就自然产生了下一个问题:存在各种各样的概率分布,编码器应该输出哪种概率分布?既然我们在潜在空间中采样时,是在一个标准高斯分布上采样的,那么从直觉上看,编码器对每个样本的输出也应该是一个高斯分布(实际上,这可以严谨推导出来,潜在变量的后验分布近似于其条件后验分布(即编码器输出)的平均,也可以理解为全概率公式,而我们对潜在变量的先验分布是标准高斯,因此为了使其后验分布尽可能接近先验分布(这是优化目标之一),编码器输出的分布也需要是高斯分布)。
这样,我们就有了VAE的优化目标:
实际上,这是一个简化的形式,在VAE中使用的是:
其中第一项衡量解码器输出与实际输入的差异程度,由于输入图片的潜在表示在某个空间下刻画了原图片的特征,因此我们希望解码器能够根据这些特征还原出原图片;第二项是正则化项,目的是最大化编码器输出的每个分布和标准正态分布之间的相似度。
此外,由于从编码器输出的分布中采样是一个不可微的操作,因此我们无法直接通过反向传播来优化这个模型,因此VAE引入了重参数化技巧:将采样操作从模型中分离出来,先从一个标准正态分布中采样一个噪声 $\epsilon$,然后通过编码器输出的均值 $\mu$ 和方差 $\sigma^2$ 来计算出潜在变量 $z$ 的值,即 $z = \mu + \sigma \cdot \epsilon$,这样就可以通过反向传播来优化模型了。
原文中有一句话说的很好,贴在这里:
- 为什么直接使用VAE往往效果不好,而使用VAE+Diffusion效果很好?
我们在采样时,假设潜在变量z服从标准正态分布,但是z有可能实际上根本就不是正态分布的,这就导致我们的采样不够精准。而扩散模型(如DDPM)本质上就是一个从正态分布(纯噪声)到真实分布(清晰图像)的映射,因此它可以很好地弥补VAE在采样时的不足。在一些更先进的模型(如Stable Diffusion)中,先采样(或通过编码器将文字转换为潜在表示)得到一个正态分布的潜在表示,然后再通过扩散模型从这个潜在表示得到符合实际分布情况的潜在表示,最终通过VAE的解码器得到最终图像,这样就可以得到更好的生成效果了。值得注意的是,这里的编码器解码器(VAE)和扩散模型(如DDPM)是两个独立的模块,它们是独立训练的,编码器解码器负责产生高效的低维潜在表示与一定随机性,扩散模型负责将这个潜在表示从正态分布过渡到符合实际的分布。
VAE相关流形(manifold)对比:
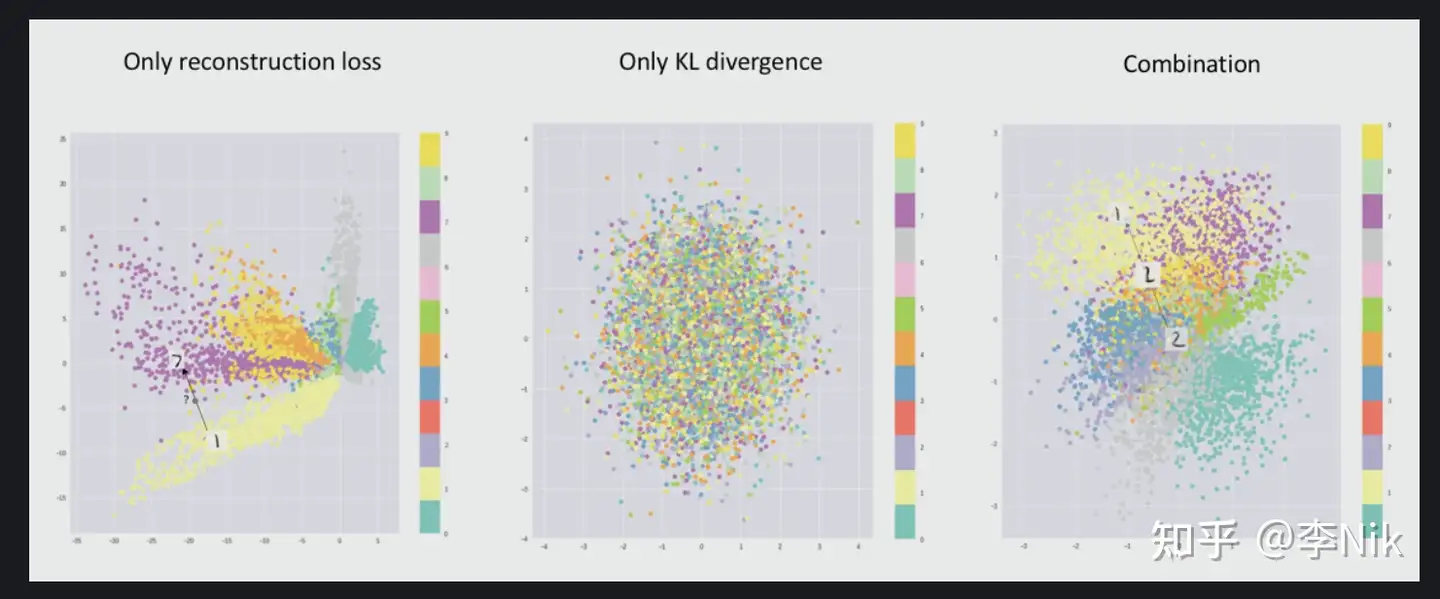
可以看到,在纯重构损失约束下,模型的流形具有明显的聚类效应,但分布极不规则,导致如果采样点落在非聚类区域,模型难以生成合理的图像;而纯KL散度约束下,模型的流形非常规则(正态分布),但各个图像种类的点杂糅在一起,导致位置相近的潜在表示可能对应完全不同的图像;使用重构损失+KL散度约束,模型结合了二者的优点。
Encoder输出的分布,既不是纯重构约束下的“聚类”分布,也不是纯KL约束下的“高斯随机”分布,而是两者的结合,既具有一定的聚类效应,又具有一定的随机性的“混合分布”。这一混合分布被认为是潜在变量z的理想分布,或者说“真实分布”,Decoder从该分布中采样得到的输出是理想结果:既具有真实性,又具有随机性多样性。而标准高斯分布显然不同于这种混合分布,因此直接从标准高斯分布中采样,喂给解码器得不到太好的结果(即纯VAE);而VAE+Diffusion则试图通过扩散模型找到从标准高斯分布到这种混合分布的映射,从而得到更好的生成效果。换句话说,我们在生成阶段无法得到编码器输出的混合分布,只能得到标准高斯,因此就需要借助Diffusion把标准高斯变成Encoder输出的混合分布。