Diffusion Transformer
原论文:https://arxiv.org/abs/2212.09748
参考:建议先看https://zhuanlan.zhihu.com/p/683657190
再看https://zhuanlan.zhihu.com/p/684125968, 会对DiT有一个相当透彻的理解
以下为Gemini概括的我在学习DiT过程中的对话内容,内容覆盖较为片面,仅供参考:
1. 核心架构:从 DDPM 到 DiT
DiT 并不是脱离传统扩散模型的全新物种,而是对现有框架的“换擎升级”。
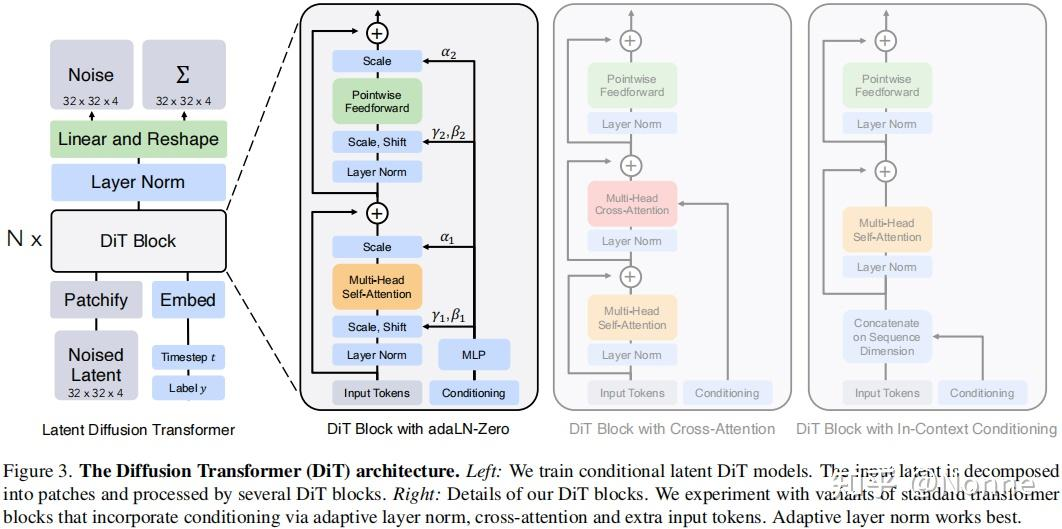
- 骨干网络替换:DiT 将传统 DDPM(去噪扩散概率模型)中基于 CNN 的 U-Net 替换成了 Vision Transformer (ViT)。
- 潜在扩散模型 (LDM):DiT 并不直接在原始像素空间生成图像,而是运行在由 VAE(变分自编码器)压缩后的 潜在空间 (Latent Space) 中。
- VAE 的双重角色:
- 训练阶段(不可或缺):使用基于 CNN 的 VAE 编码器,将高分辨率图像压缩为低维潜在表示(建立潜在空间的数学分布),大幅降低 Transformer 的计算开销。
- 推理/采样阶段:仅使用 VAE 解码器,将 DiT 在潜在空间去噪完毕的张量还原回人类可见的像素图像。
2. 数据维度与张量流转
对话详细解析了图像和条件在模型内部是如何变换形状的。
- 潜在表示 ($z$) 的形状:对于 256x256x3 的原始 RGB 图像,经过 8 倍下采样的 VAE 后,高度和宽度变为 32,通道数为了特征提取扩展为 4。因此进入 DiT 的特征图形状为 32x32x4。随后该特征图会被
patchify操作切分为 token 序列。 - 时间与类别的嵌入 (Embeddings):
- 时间步 $t$:标量通过正余弦编码转化为频率向量,再通过 MLP(多层感知机)升维至隐藏层维度 $D$。
- 类别 $c$:通过查表(Embedding Table)映射为 $D$ 维稠密向量。
- 融合:时间步向量与类别向量直接相加,形成形状为 $(N, D)$ 的综合条件向量($N$ 为批大小 Batch Size),作为后续网络控制的基础。
chunk函数的作用:PyTorch 中的切分函数,在 DiT 中像“平分刀”一样用于拆解高维输出。例如将预测输出拆分为噪声和方差,或将推理时的批次拆分为有条件输出和无条件输出。
3. 核心组件:DiT Block 的内部机制
Transformer 块在 DiT 中为了适应扩散任务做了专门的定制。
- AdaLN-Zero (自适应层归一化):
- 传统的 LayerNorm 会在特征维度上计算均值和方差,并使用固定的缩放因子 $\gamma$ 和偏置 $\beta$。
- DiT 使用 AdaLN,其 $\gamma$ 和 $\beta$ 是动态的。融合后的 $(N, D)$ 条件向量会被送入一个 MLP,用于回归预测当前层所需的 $\gamma$、$\beta$ 以及残差块的门控系数 $\alpha$。
- 初始化:相关参数被初始化为零(即 Zero),使得模型在初期等效于恒等映射,极大地增强了深层网络的稳定性。
- 激活函数:
- GELU:结合了 ReLU 的确定性和 Dropout 的随机性,通常用于 Transformer 的前馈网络(FeedForward)中。公式为 $x \cdot \Phi(x)$。
- SiLU (Swish):平滑且非单调,通常用于 MLP 层(如时间步嵌入的升维网络)中。公式为 $x \cdot \sigma(x)$。
4. 预测目标:双管齐下(噪声与方差)
DiT 继承了 Improved DDPM 的策略,输出维度被设定为 $2 \times C$,同时预测均值(去噪方向)和协方差(随机扰动范围)。
- 预测噪声 ($\epsilon$):指导模型如何将当前状态向真实图像的分布(均值)靠拢。
- 预测方差 ($\Sigma$ / $v$):模型不直接预测方差绝对值,而是预测一个插值系数 $v$,在理论最大方差和最小方差之间进行对数空间插值,计算出采样公式 $x{t-1} = \mu\theta(xt, t) + \sigma\theta(x_t, t) \cdot z$ 中的 $\sigma$。
- 预测方差的意义:极大地提升了模型在少步数采样(如从 1000 步压缩至 250 步)时的生成质量,优化了对数似然估计,并消除了手动调节方差时间表的麻烦。
5. 训练机制与损失函数
训练过程是让模型学会如何去噪并掌握数据分布。
- 双重损失函数:
- 噪声损失 ($Loss_{mse}$):使用均方误差 (MSE) 衡量模型预测噪声与实际添加噪声的差异,确保“去噪位置”的准确性。
- 方差损失 ($Loss_{vlb}$):使用 KL 散度(计算变分下界)衡量模型生成的分布与真实后验正态分布之间的差异,确保“去噪分布”的准确性。
- EMA (指数移动平均) 权重:
- 训练中并行维护两套权重。在线模型通过梯度下降实时更新;EMA 模型(影子模型)通过公式 $\theta{EMA}^{new} = 0.9999 \cdot \theta{EMA}^{old} + (0.0001) \cdot \theta_{current}$ 缓慢跟随。
- 意义:过滤梯度更新的随机噪声,获得更平滑、稳定且泛化能力更强的权重。DiT 论文中的 SOTA 结果均使用 EMA 模型生成。
6. 生成控制:无分类器引导 (CFG)
这是平衡图像生成多样性与质量/标签契合度的核心技术。
- 训练时的随机丢弃:训练阶段以一定概率(如 10%-20%)将类别标签替换为空条件($\varnothing$)。这使得同一个模型既学会了生成特定类别的图像(有条件),也学会了生成整个数据集的“平均/平庸”噪声特征(无条件)。
- 推理时的差值放大 (线性外推):
- 采样时,模型对同一输入分别运行有条件和无条件两次预测。
- 通过核心公式:
- 以无条件输出(平均噪声)为基准,利用引导系数 $s$ (
cfg-scale) 放大条件特有的特征。$s$ 越高,特征越强烈,但可能显得生硬;$s=1$ 表示纯条件预测,无放大。
- 工程细节:CFG 的混合外推操作仅针对均值(预测噪声)生效,以引导图像长得更像标签;而预测出的协方差(方差)部分则直接采用有条件分支的输出,不参与 CFG 混合。
7. 核心性能指标
DiT 证明了 Transformer 在视觉扩散任务中具有极强的可扩展性(Scalability)。
- GFLOPS:衡量模型计算复杂度的指标。DiT 通过增加网络深度、宽度和 token 数量来提升 Gflops。
- FID (Fréchet Inception Distance):衡量生成图像质量与多样性的指标(越低越好)。随着 Gflops 的增加,DiT 的 FID 稳定下降。DiT-XL/2 (256x256) 凭借 119 Gflops 达到了 2.27 的业界 SOTA FID 成绩。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Qz's Blog!