Just image Transformer
原论文:https://www.alphaxiv.org/abs/2511.13720
参考:https://zhuanlan.zhihu.com/p/1977479109690032906
https://zhuanlan.zhihu.com/p/1974626511182124468
1.扩散模型的发展历史
在生成式模型领域,如GAN相比,扩散模型(如DDPM)一直被诟病的一个问题就是它的计算效率较低,因为像DDPM这样的模型的增噪,采样,去噪过程全部都是在原始图像的像素空间(pixel space)中进行的,除非图片的分辨率非常小(如16x16x3),否则该pixel space的维度是非常高的,导致模型的计算量和内存占用都非常大。ADM对DDPM进行了改进,但与GAN相比,效率依然差得很远。为了提升模型效率,Latent Diffusion Model(LDM)架构被提出,该架构包含一个VAE编码器,用于将图片从pixel space映射到一个低维的latent space中;一个针对latent space中潜在图像的扩散模型(起初是基于U-net的,后来被DiT取代),用于将一个随机分布的latent representation逐渐去噪成一个符合实际分布的latent representation;一个VAE解码器,用于将去噪后的latent representation映射回pixel space中的图像。LDM由于显著降低了输入的维度,从而大幅减少了传给扩散模型的序列长度,从而在效率与质量上都取得了不错的表现。现有的生成模型也大多基于LDM架构,如Stable Diffusion,Midjourney,Gemini Pro等。
2.问题
既然基于latent space的扩散模型表现这么好,我们还有必要研究基于pixel space的扩散模型吗?答案是肯定的,首先,对于某些超高清图像的编码和生成,直接将其映射到latent space中可能会丢失一些细节信息;其次,当某些图像难以进行VAE编码时,我们希望直接在原图上进行处理;最后,在未来,长视频的理解和生成可能成为热点,而视频一秒就包含30-60帧,即使我们通过latent space使得单张图片传给扩散模型的序列长度变短,但是在视频的尺度下,由于模型需要理解视频上下文的语义关系,那么它需要接收的序列依然是非常长的,这无法通过LDM架构来解决。因此,我们有必要研究如何在长序列上使用Transformer来进行图像生成。
3.基于pixel space扩散模型的研究
一些研究将U-net或U-ViT应用到像素空间,虽然计算更为复杂,但也取得了不错的表现,他们发现,为了使每一步的信噪比不随序列长度(图像分辨率)改变,对于分辨率更高的图像,在每一步需要添加更多的噪声,这样有利于提高模型性能。那能否在pixel space中使用DiT呢?首先,我们之所以要先使用VAE编码,再将其送入DiT,是因为transformer的计算复杂度是O(n^2),如果直接将原图送入transformer,那么计算量会非常大。也就是说,我们必须找到一种有效的压缩方式,最直接的就是借鉴ViT中的patchify方法,将图像切分成小块,每块作为一个token送入transformer中,然而,实验发现,如果采用p=2(patch size的意思)的patches,DiT可以取得较好的性能,但这样patch太小,序列依然很长;如果采用更高的p(>=4),虽然可以大幅降低序列长度,但模型性能会急剧下降。这是因为这种压缩损失了太多的信息(其实还有一个更重要的原因,后面会讲)。
4. Just image Transformer (JiT)
基于以上问题,JiT试图得到一个不带任何额外设计,且 patch size 较大的 pixel DiT。JiT所做的其实很简单:把DiT的预测目标从v换成x。
首先,任意扩散模型在每一步的预测目标基本上有三种:当前图像与实际图像的噪声 $\epsilon_t$ (早期DDPM使用),当前图像到目标图像的速度 $v_t$ (速度 $v_{target} = \alpha_t \epsilon - \sigma_t x_0$ ,对应某点在图像-噪声球体上的切线方向,由当前图像和噪声计算得出,可看作是某种噪声的变体,比直接预测噪声效果更好),以及希望预测的目标图像 $x_1$ (注意,和早期的 DDPM 相反,这里时刻 0 时图像为纯噪声,时刻 1 时图像为清晰图像)。简单来讲,当前图像加上速度就等于目标图像,即 $x_t + v_t = x_1$。而当前图像在每一步是已知量,因此我们只要知道速度或目标图像的任意一个,就能得到上面的所有信息。
目前最常用(最初提出)的 rectified flow 加噪公式为:
这个公式非常简单,就是清晰图像和噪声之间的线性插值。
论文中的速度 $v_t$ 的计算方法: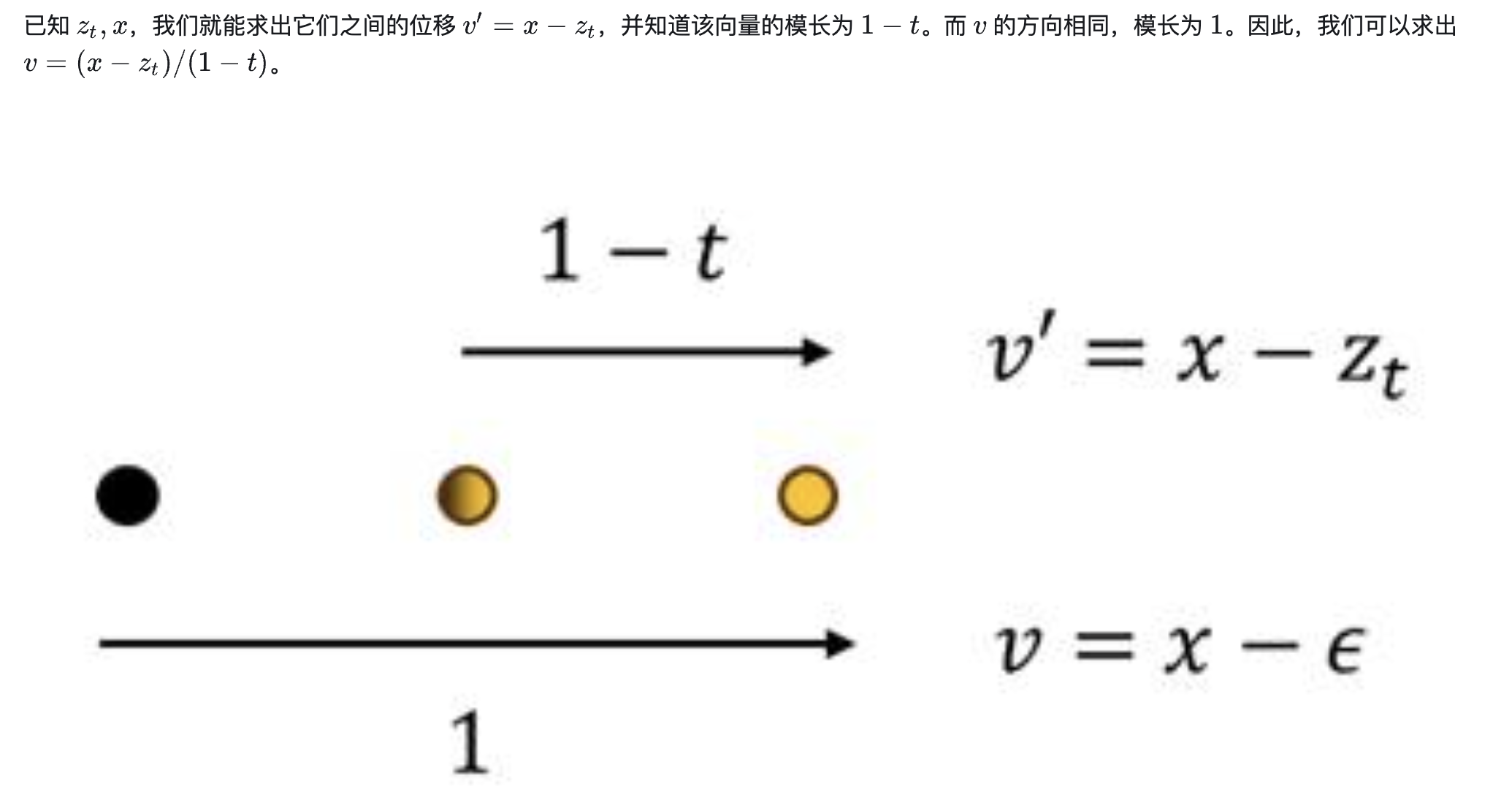
尽管扩散模型的三种预测目标之间可以转换,但神经网络学习预测三种目标的难度是不同的。JiT考虑了以下两个方面:
- 该让模型输出哪个预测目标?
- 该拿哪个预测目标计算损失?
由于网络输出的目标之间可以互相转换,所以第一步和第二步可以用不同的预测目标,例如,我们可以让模型输出 $x_\theta = network(x_t, t)$,然后用 $v_\theta = (x_\theta - x_t)/(1-t)$ 来计算速度,再用 $v_\theta$ 和 $v_{target}$ 来计算损失。JiT的消融实验表明,让模型输出 $x_\theta$,但使用v-loss是最优的。
JiT还使用了一些其他技术来提升性能:
- 噪声强度偏移.使用了 SD3 的 logit-normal t 采样技术
- Bottleneck 嵌入层.原来 DiT 在将输入通道数变成模型通道数时,只会用一个普通的线性层。而 JiT 把它换成了一个双层 bottleneck 结构:先降维,再升维到模型通道数。
- 现代 DiT 结构.参考之前的 LightningDiT (即提出了 VAVAE 的论文),对 DiT 的模块进行了改进,使用了 SwiGLU, RMSNorm,并将位置编码换成了 RoPE,还加入了 qk-norm
- 针对 class condition 的优化.将单个类别 token 拓展成了 32 个类别 token。此外,JiT 还用了一种叫做 CFG interval 的技术,能够提升 CFG 的采样质量

值得说明的是,由于JiT的提出是基于高分辨率/长序列的需求,在这样的需求下,不得不采取较大的patch size。而较大的patch size会导致一般模型失效,因此JiT提出了此方法来使得在大patch size下模型依然能够取得不错的性能。换句话说,JiT是一个针对大patch size特化的扩散模型,假如资源条件允许,用原来 v-prediction 的小 patch size DiT模型实际上能取得比JiT更好的性能,当p=2时,DiT的性能甚至与完全不进行patchify(p=1,即理论上的性能上限)相差无几。所以参考文章认为,”大 patch size 的 DiT 用 x-prediciton 更优”才是论文的真正结论。
处理流程,来源https://zhuanlan.zhihu.com/p/1974626511182124468:
5.流形假设
JiT设计的核心理念与根本动机是流形假设。流形可以看作是高维空间中对象的某种低维表达,例如,地球仪是个三维球体,但是上面的每一点只需要用经纬度两个坐标就能表达,那么将球面展开形成的这个二维平面,就可以看作是地球仪上所有点的流形。流形假设认为,高维空间的数据集里的数据并不是均匀分布在整个空间里,而是在一个低维流形上。换句话说,虽然真实世界中的图像可能具有很高的维度,但它们完全可以由某种低维的形体/规律再加上一些噪声来刻画。而噪声和速度完全是从高维空间中随机采样得来的,它们不具有任何规律,因此也就不符合流形假设。JiT认为,符合流形假设的数据更容易被神经网络预测,因为它们本就具有某种潜在的规律,因此模型不再预测噪声或速度,而是预测符合流形假设的图像本身。为了证明这个命题,JiT还做了一个迷你实验,作者将一个 2D 图形用一个维度为 D 的随机投影矩阵投影到了 D 维。接着,作者训练了三个预测目标不同的扩散模型,观察哪个模型能够成功预测这个投影后的 D 维数据。结果发现,随着 D 增加,只有 x-prediction 维持不错的预测效果,预测噪声和速度都不行。
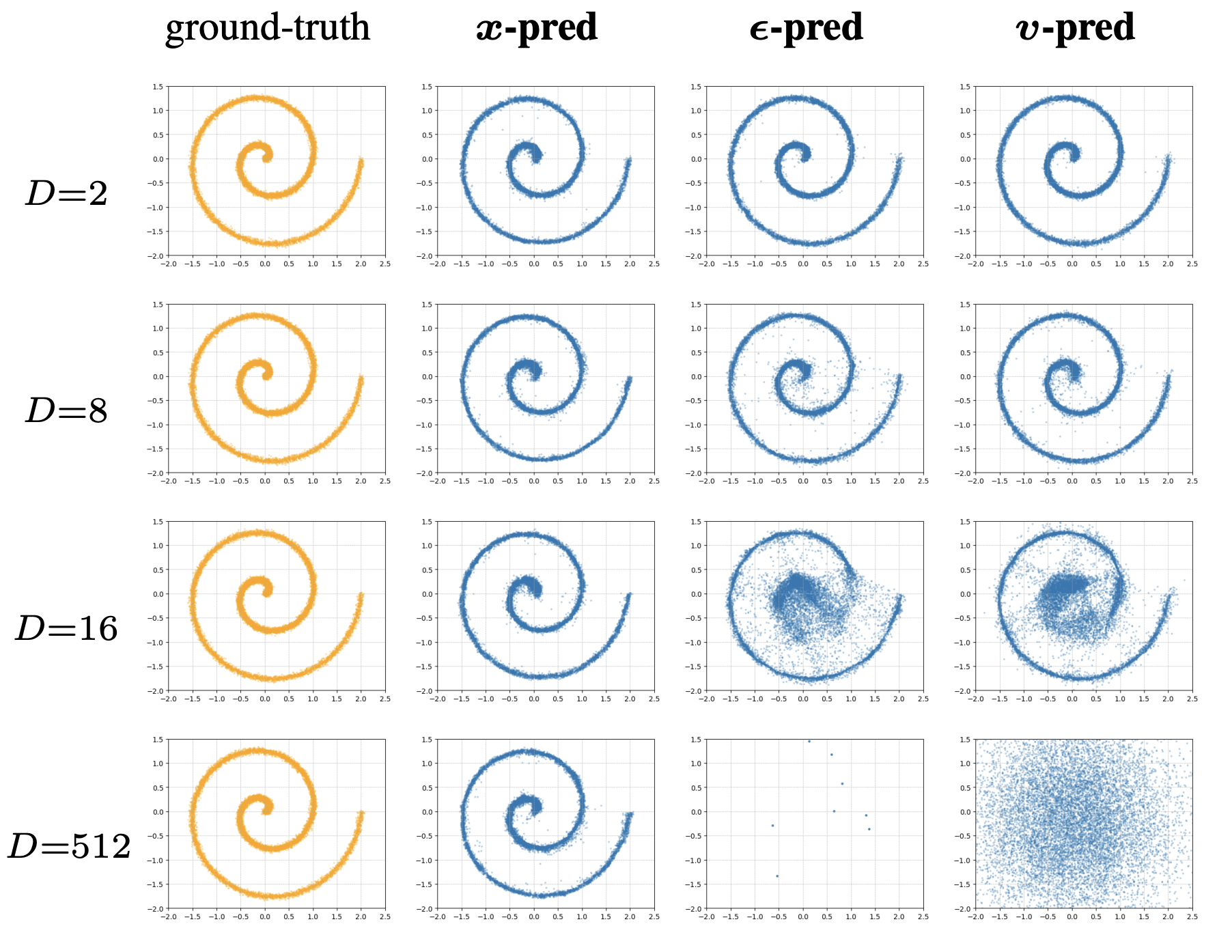
流形假设也可以很好的解释噪声预测与速度预测模型在大patch size下性能下降的原因。假如patch size为p,通道数为3,那么每个token的维度就是3*p^2,当p较小时,DiT在计算上没有性能压力,并且分块更为精细,因此可以很好的预测出噪声或速度;当p较大时,每个token的维度变得很高,假如模式试图预测噪声或速度,那么它就需要在高维空间中进行预测,而高维空间中的噪声和速度是完全随机的,不具有任何规律,因此模型很难学习到它们的分布,并且ViT的patchify方法本身就具有信息瓶颈,它会导致信息的丢失,对毫无规律的噪声而言,这种信息丢失会不断累积放大,最终导致模型预测差之千里;相反,如果模型预测的是图像本身,那么它的预测对象就符合流形假设,具有某种潜在规律,ViT的信息瓶颈此时反而有利于强迫模型学习到这种深层的低维潜在规律,于是模型更容易预测出正确的高维图像。因此x-prediction的任务(投影到流形)和ViT的特性(信息瓶颈)完美契合。而ϵ/v-prediction的任务(传递高维随机信息)和ViT的特性是根本矛盾的。
6.补充
另一个有意思的点是,JiT的代码中对速度的计算v = (x - z) / (1 - t).clamp_min()和v_pred = (x_pred - z) / (1 - t).clamp_min(),然后损失loss = mse(v_pred, v),这里两个v中的z项其实在相减时被抵消了,因此损失等价于loss = mse(x_pred/(1-t), x/(1-t)),因此x-loss 和 v-loss 的唯一区别就是后面的 /(1-t)。越是靠近清晰图像,1-t 越靠近 0,loss 权重更高;反之,越靠近噪声,loss 权重越低。所以,不同的 loss 其实就是在不同的 t 时用了不同的权重而已。这也与前人的经验相一致。
7.总结和启发
- JiT 的贡献或许和是否有隐空间无关,它是一种适用于任何数据的,提升大 patch size DiT 生成质量的方法
- 研究扩散模型一定不能仅仅死磕数学推导,仅用数学理论完全无法解释要用哪种 loss,以及为什么如何不同 t 时设置不同的权重,这些公式对调优扩散模型的结果也帮助甚微。AI是基于经验和实验的学科,必须要像物理一样从现象中归纳,而不是像数学一样基于演绎推理,很多时候是先有了网络与数据,然后再考虑配套的公式推导,而不是先提出一个高大上的公式变量,再想办法用神经网络去预测/拟合它,一定要从实践的角度,充分考虑神经网络本身的特性。