SwinIR
原论文:https://arxiv.org/abs/2108.10257
参考:https://zhuanlan.zhihu.com/p/558789076
https://deepwiki.com/JingyunLiang/SwinIR
前言
在图像修复(Restoration),去噪(Denoising),超分辨率(Super-Resolution,SR)等领域,CNN由于其优越的归纳偏置展现出与CV任务极强的适配性,然而CNN有几个致命的缺陷:
首先,卷积核中的参数对于图像的每个区域都是固定的,无法根据图像的上下文动态调整,其次卷积依赖于locality假设,在长距离建模中表现不佳,由此引出了与Transformer结合的视觉模型
ViT,然而ViT也有几个问题,首先ViT使用的patches在每一层都是一样的(包括大小和位置),这就导致恢复后的图像可能会在每个patch周围引入边界伪影,其次patchify操作导致边界像素不能利用patch之外的邻近像素进行图像恢复。
SwinIR
Swin Transformer很好的结合了CNN与ViT的优点,SwinIR则是将Swin Transformer应用于图像修复领域的一个模型,它在显著更小的参数下,实现了超越SOTA的性能表现,并且有很强的可扩展性。
SwinIR的架构如下: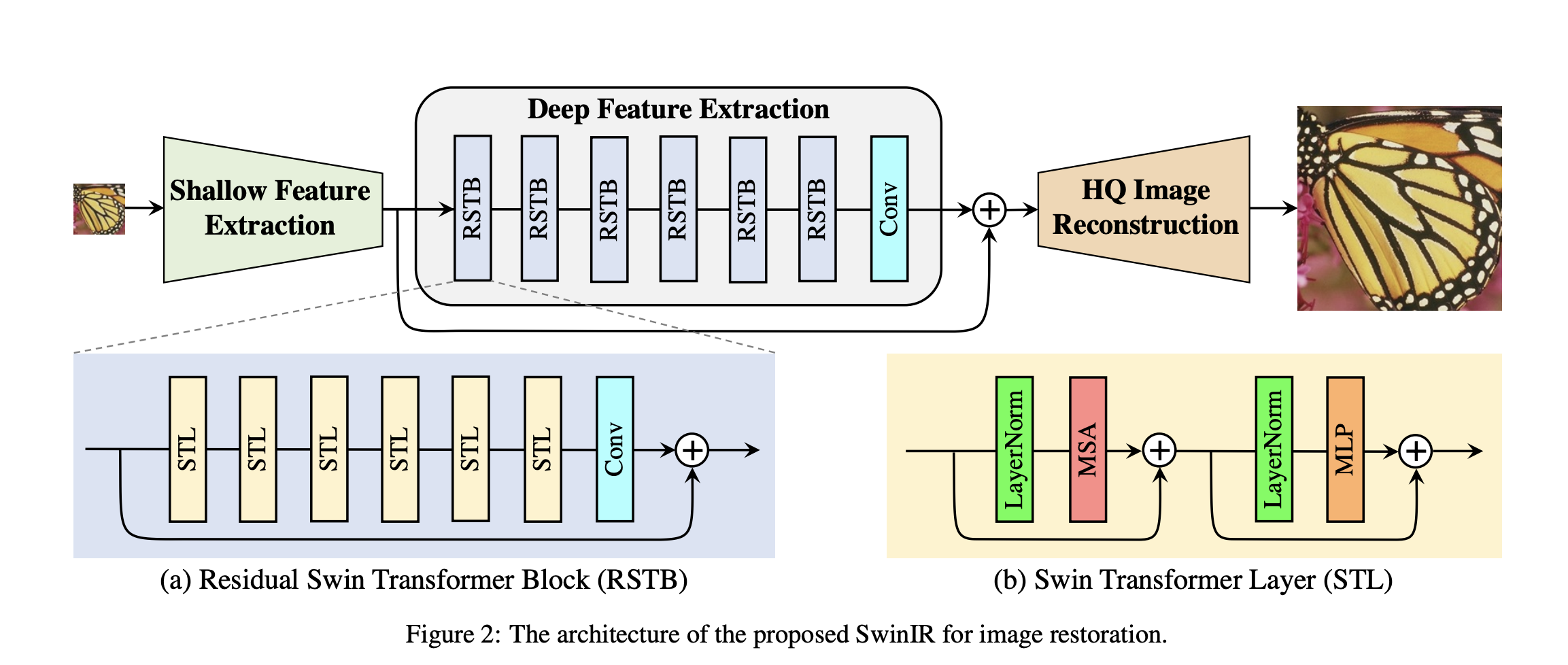
SwinIR包含三个部分:浅层特征提取模块shallow feature extraction、深层特征提取模块deep feature extraction、图像复原模块highquality (HQ) image reconstruction modules
其中前两个特征提取模块对于所有图像复原任务都是相同的,负责提取出不同层次的特征图,而图像复原模块则根据不同的任务进行调整。
shallow feature extraction
浅层特征提取模块很简单,即用一个3×3卷积HSF提取浅层特征F0:
其中 $I_{LQ}$ 是输入的低质量图像,$F_0$ 是提取出的浅层特征图。
deep feature extraction
将提取到的浅层特征F0,使用深层特征提取模块HDF进一步提取特征。深层特征提取模块由K个residual Swin Transformer blocks(RSTB)和一个3×3卷积构成。
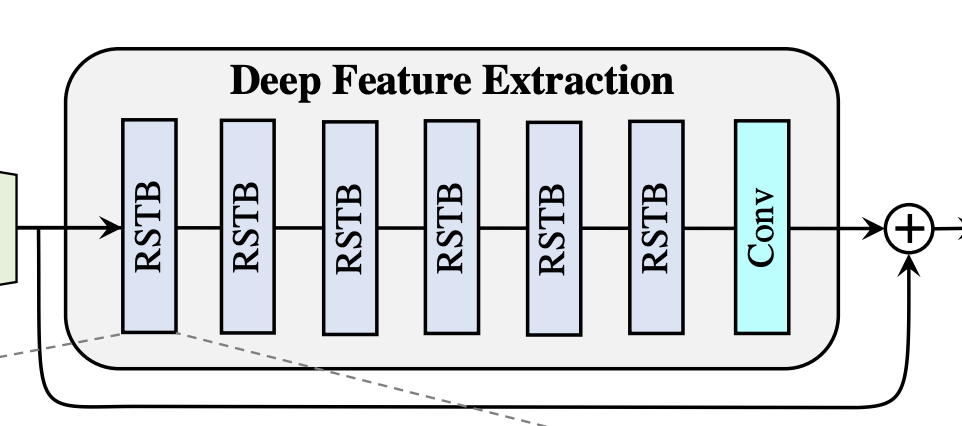
卷积层能够将卷积的归纳偏置引入基于Transformer的网络,增强平移等变性(保证了图像特征无论出现在画面的哪个位置,模型都能进行一致的处理),为后续浅层、深层特征的融合奠定基础
Fmixed通过将深层特征图FDF与浅层特征图F0逐元素相加得到,是融合了浅层和深层特征的特征图。
其中每个RSTB的结构: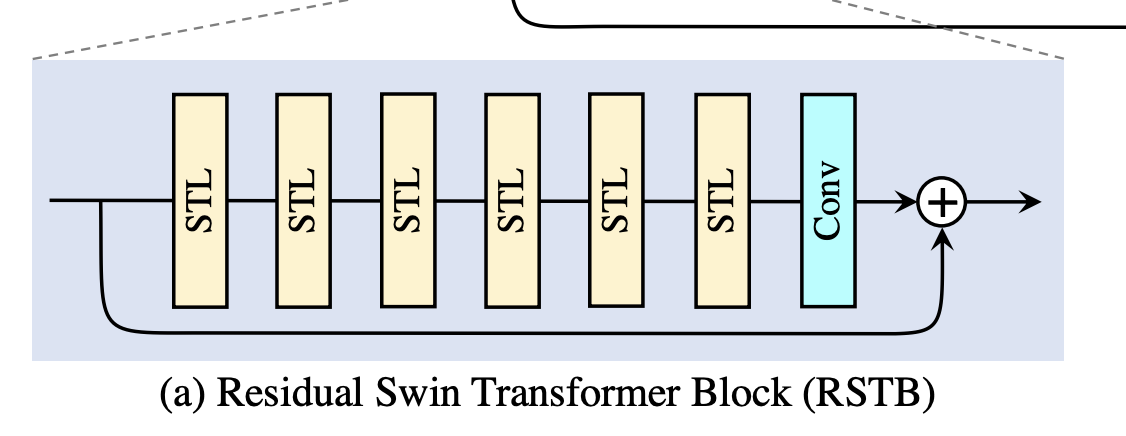
residual Swin Transformer block (RSTB)由残差块、Swin Transformer layers (STL)、卷积层构成。卷积操作有利于增强平移不变性,残差连接则有利于模型融合不同层级的特征。每个STL层的结构如图: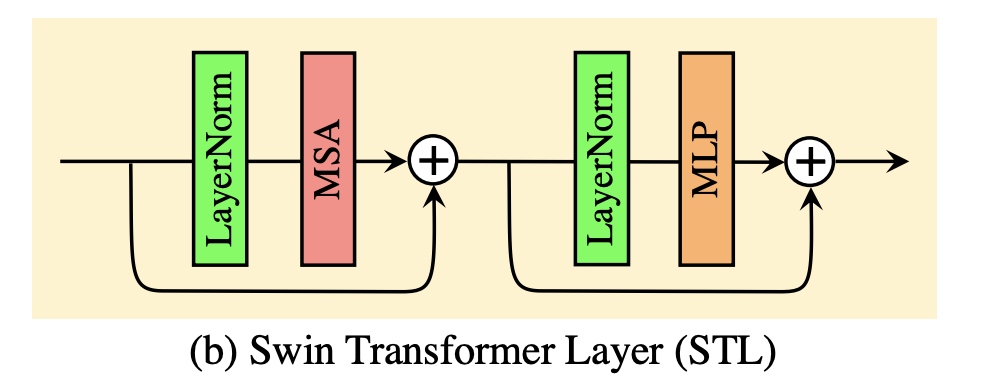
这里简单回忆一下Swin Transformer:首先我们需要搞清楚Transformer的自注意力(MSA)究竟做了什么:它的输入是一段序列,长度为l,维度为d,输出也是一段序列,长度也为l,维度也为d,只不过其中的每个token对应的d维向量不再仅仅表示它自己,而是表示“融合了上下文信息的该token的语义”,也就是说MSA不会改变输入的形状,只是在每个token的语义上做了增强。从这个角度看Swin Transformer,他最重要的组成部分其实就两个:窗口自注意力模块(W-MSA)和移位窗口自注意力模块(SW-MSA)。这两个模块的内部结构是很像的,都是LN->MSA->残差连接->LN->MLP->残差连接,唯一的区别就是前者是基于窗口的MSA,而后者是基于移位窗口的MSA。这两个MSA在内部做了一些较为复杂的操作(可以看我的往期文章),但他们本质上都是MSA,也就可以看成是在不改变输入形状的情况下增强了每个token的语义。
这样,就可以解释RSTB了:RSTB由多个STL和一个Conv堆叠而成,其中在所有STL中,W-MSA和SW-MSA块交替出现,分别用于在可接受的复杂度内计算局部依赖关系和长距离依赖关系,Conv层则用于增强平移不变性,残差连接用于模型融合不同层级的特征。
image reconstruction module
这是一个可以根据实际任务更换的输出头。
对于SR任务,通过融合浅层特征F0和深层特征FDK来重建高质量图片IRHQ,式中HREC为重建模块
浅层特征F0主要包含低频信息,而深层特征则专注于恢复丢失的高频信息。SwinIR采用一个长距离连接,将低频信息直接传输给重建模块,可以帮助深度特征提取模块专注于高频信息,稳定训练。这里的“低频”和“高频”指的是图像中像素值在空间上变化的剧烈程度。
在图像超分辨率任务中,通过sub-pixel convolution layer将特征上采样,实现重建。
在其他任务(去噪和JPEG伪影消除)中,则是采用一个带有残差的卷积操作
其中HREC为重建模块,使用一个单独的卷积层实现,ILQ是输入的低质量图像,IRHQ是重建后的高质量图像。
这里实际上表达了深度学习图像恢复中极为重要的一种思想——全局残差学习(Global Residual Learning)。对于像去噪(Denoising)或去JPEG压缩伪影这样的任务(这类任务不需要放大图片尺寸),直接让模型“画”出一张完整的高清图是很困难的。因此,这里的意思是:模型 $H_{SwinIR}(I_{LQ})$ 实际上不去预测完整的高清图像,而是去预测低清图和高清图之间的“差异”(即残差,比如单纯的噪点图或丢失的细节图)。我们把模型预测出来的这个“差异(残差图)”直接加到原始的低清图 $I_{LQ}$ 上,就得到了最终的高清复原图 $I_{RHQ}$ 。这种做法极大地降低了模型的学习难度。
损失函数
图像超分辨率任务采用L1损失,通过优化SwinIR生成的高质量图像IRHQ及其对应的标签IHQ的来优化模型。
图像去噪任务和压缩任务采用Charbonnier loss,式中ɛ通常设置为10-3。
- L2损失对异常值(Outliers)非常敏感,容易导致生成的图像过于模糊,L1损失在零点处不可导,且在某些优化场景下不够稳定。Charbonnier loss 其实是经典的 $L_1$ 损失的一种平滑近似版本,纯粹的 $L_1$ 损失在误差正好为 0 的那一点是“尖锐”的(不可导),这在神经网络反向传播计算梯度时不够完美。通过在根号内引入这个极其微小的常数 $\epsilon^2$,Charbonnier loss 巧妙地把那个“尖角”磨平了,让整个损失函数在任何地方都变得极其平滑且处处可导。同时,当模型预测误差稍微变大一点点时,它的表现又和 $L_1$ 损失几乎一样,这意味着它对异常值(比如特别严重的噪点或极端的伪影)具有很强的鲁棒性,不会像 $L_2$ 损失(均方误差)那样导致生成的图像过于平滑和模糊,从而有助于保留图像锐利的边缘,具有平滑性,鲁棒性,收敛更好的优点。
SwinIR的实践
SwinIR具有多种规模与配置,对于SR任务,该模型包括经典图像超分辨率(Classical image SR),轻量级图像超分辨率(Lightweight image SR)和Real-world image SR。由于结合了Swin Transformer的高效性和CNN的归纳偏置,SwinIR在各种任务上都以较小的参数量实现了优越的性能表现。
总结
SwinIR模型遵循目前超分网络中head+body+tail的通用结构,通过引入Swin Transformer作为深层特征提取模块,成功地结合了CNN的归纳偏置和Transformer的全局建模能力,在图像修复领域实现了显著的性能提升。SwinIR的设计理念和架构为未来图像修复任务提供了一个强有力的基线,并且其可扩展性使得它能够适应不同的图像修复需求。
补充
关于“JPEG伪影消除”:JPEG是一种有损压缩算法,在压缩过程中会丢失一些图像细节,尤其是在较高压缩率下,这些丢失的细节会以“伪影”的形式表现出来,包括:
- 块状效应:JPEG 算法会将图片分成许多 $8 \times 8$ 像素 的小方块进行处理,产生“马赛克”
- 振铃效应:通常出现在物体的高对比度边缘,边缘周围会出现像“回声”一样的杂点或细微的重影,这是因为在丢弃高频信号(细节)时,数学公式(离散余弦变换)在还原边缘时产生了误差
- 蚊式噪声:振铃效应的一种特殊形式,在锐利的边缘或精细的纹理处,会出现像“蚊子乱飞”一样的细小随机杂点