SRGAN,ESRGAN,RealESRGAN
论文:
- SRGAN:https://arxiv.org/abs/1609.04802
- ESRGAN:https://arxiv.org/abs/1809.00219
- RealESRGAN:https://arxiv.org/abs/2107.10833
参考:https://zhuanlan.zhihu.com/p/595533046
https://zhuanlan.zhihu.com/p/542750836
SRGAN
SRGAN,即Super-Resolution Generative Adversarial Network,是一种基于生成对抗网络(GAN)的图像超分辨率方法。SRGAN的核心思想是通过一个生成器网络,输入低分辨率的图像,生成高分辨率图像,并使用一个判别器网络来评估生成图像的质量,从而使生成的图像尽可能接近真实的高分辨率图像。与传统的GAN不同,SRGAN引入了内容损失(Content Loss),该损失函数不仅考虑像素级的差异,还考虑了图像的高层次特征,从而能够生成更具视觉质量的图像。
其中第一项内容损失的计算是基于一个VGG19的预训练模型,将生成器的输出传入该模型,经VGG模型前向传播后使用经过其激活层RELU后的特征,分别得到GT_HR与Gen_HR经过VGG19特定层的feature map, 进行一个欧式距离的计算(即MSE),得到内容损失$l_{X}^{SR}$。
第二项对抗损失的计算则是将生成器的输出传入判别器,得到一个概率值,表示生成图像被判别器认为是真实图像的概率,取其对数并乘以-1,得到对抗损失$l_{Gen}^{SR}$。
- SRGAN还发现使用VGG越深层的特征图,表征特征更抽象,更远离像素空间,从而图像在感知效果上会更好。但是使用更深的网络,训练变的不稳定,生成数据会有伪影。
ESRGAN
ESRGAN,即Enhanced Super-Resolution Generative Adversarial Network,是SRGAN的改进版本,主要修改了以下四个方面:
生成器架构修改
对生成器网络引入了一个残差密集连接模块Residual-in-Residual Dense Block (RRDB), 并且去掉了网络中所有的BN层,并且加入一个残差scaling操作使能够训练更深的网络结构。
在SRGAN中,每个Basic Block就是一个Residual Block,而在ESRGAN中,每个Basic Block是一个RRDB,RRDB包含了三个Dense Block,每个Dense Block包含了五个卷积层,并且每个卷积层都与后续的卷积层进行连接(每个卷积层都以前面所有卷积层的输出作为输入),形成密集连接结构。RRDB取消了RB中的BN,因为BN对图像的像素分布进行归一化,这会破坏图像原有的亮度信息和对比度,而且会导致生成的图片中含有伪影。此外,residual scaling操作, 即残差分支在加到主path前,乘以一个0-1之间的常数,能够更好的训练一个更深的网络。RRDB的输入和输出之间还有一个残差连接,这样可以更好地传递信息,避免梯度消失问题。如图:
感知损失的改进
ESRGAN使用了VGG网络中经过激活函数前的特征图而不是激活函数后的特征图来计算内容损失,主要是因为激活函数会减弱图像的特征,激活之后的特征非常的稀疏,从而导致效果不好,并且使用激活后的特征发现重构出来的图片与GT的亮度不一致,使用激活前的特征则能够更好的保持图像的亮度信息。
对判别器输出的改进
ESRGAN使用了一个相对判别器(Relativistic Discriminator,简称RaGAN)。普通判别器中,输出的是图片为真的绝对概率,对真图和假图的判断是孤立的,这会导致训练不够稳定,且生成出的纹理有时会显得生硬或不自然。相对 $D_{Ra}$会将真图 $x_{real}$ 和假图 $x_{fake}$ 成对考虑。它计算的是:
(通俗理解:真图的分数 减去 假图分数的平均值,再过一个激活函数。这里的C是指判别器的非激活输出,即传给sigmoid的原始数值,分数越高,判别器越觉得它是真的)
在训练D时,D的目标是最大化 $D_{Ra}(x_{re}) = \sigma(C(x_{re}) - \text{mean}(C(x_{fa})))$和最小化 $D_{Ra}(x_{fa}) = \sigma(C(x_{fa}) - \text{mean}(C(x_{re})))$,也就是说,D的目标是让真图的分数尽可能高于假图的分数。而在训练G时,G的目标则是最大化$D_{Ra}(x_{fa}) = \sigma(C(x_{fa}) - \text{mean}(C(x_{re})))$和最小化 $D_{Ra}(x_{re}) = \sigma(C(x_{re}) - \text{mean}(C(x_{fa})))$,也就是说,G的目标是让假图的分数尽可能高于真图的分数。通过这种相对判别器的设计,G不仅在模仿真图,还在通过对比主动寻找真图里那些自己还没学会的特征,此外,因为 $G$ 的 Loss 里引入了真图的统计量(均值),所以即使某个 Batch 的假图画得特别烂,由于有真图作为参照物(Baseline),传回给 $G$ 的梯度也不会瞬间爆炸或消失,从而梯度更稳定。通过将将判别器的关注点从绝对值转向差值,生成的图像在细节上不再是杂乱的噪声,而是更具结构感的高频纹理。
网络插值
为了去掉基于GAN方法引入的一些噪声,ESRGAN先训练一个PSNR导向的网络(以最大化PSNR或最小化生成图像与真实图像的MSE为优化目标),再训练一个GAN的模型,从而得到一个插值的模型:
这样做可以消除 GAN 带来的“伪影”和“噪点”;通过调整 $\alpha$(从 0 到 1)合成无数个不同风格的模型,无需重复训练;避免了图像层的“重影”问题。平衡了感知质量和真实性。
- 在ESRGAN中,更深的模型不仅能减少生成图像的噪声,而且还能改善恢复出来的HR的纹理细节,因为越深的模型,捕捉语义信息的能力越强。
RealESRGAN
RealESRGAN,即Real-World Super-Resolution Generative Adversarial Network,是ESRGAN的进一步改进版本,主要针对现实世界中的图像超分辨率任务进行了优化。我们知道,超分辨率算法是在学习从低清图像到高清图像的映射,而现实中的从高清图像到低清图像的退化是复杂且多样的,SR模型在训练时很难囊括所有可能出现的图像退化类型,所以SR算法在真实场景中受限,往往在一批数据上训练的模型在另外一批数据上表现就不佳,也就是泛化性不佳。因此,我们希望得到一个可用于真实场景中的泛化性强的模型,就需要先解决退化图像数据的问题,如何获得与真实退化图像最接近的训练图像数据呢?
由于我们很难收集真实世界中的成对LR-SR图像数据(图片要么是高清的,要么是低清的),因此我们只能自己从HR数据中创造LR数据,通过完全模拟的数据训练。SR算法根据所得LR图像的退化过程分为两类:一类是显式建模,即通过模型手动对对HR进行退化,例如模糊、下采样、噪声和JPEG压缩,但是简单的退化组合难以完全覆盖真实数据,所以导致模型泛化性不佳;另一类是隐式建模,即通过一个GAN网络来学习从HR到LR的退化映射,但使用GAN所得数据也会让生成的数据趋于训练集的分布,当训练集的分布单一时所得LR也很单一。因此,RealESRGAN认为,一个真实的复杂退化由不同的退化过程组合而成。RealESRGAN将经典的一阶退化扩展为高阶退化模型,第i-1阶退化的输出作为第i阶退化的输入,期望通过”高阶“退化可以得到和真实退化更接近的LR数据。在论文中,使用的是二阶退化。
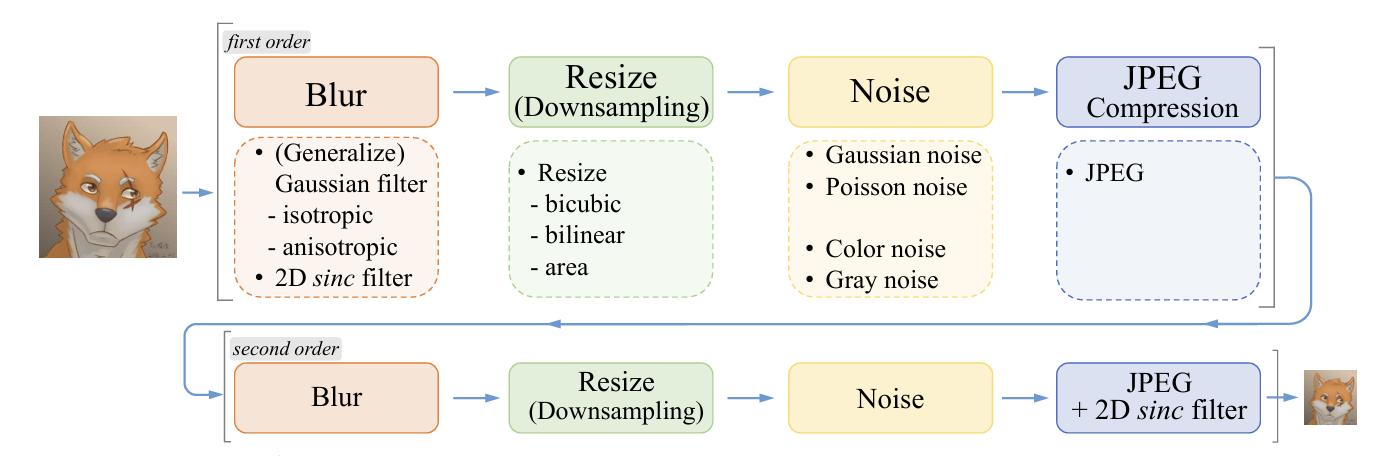
高阶退化
每个一阶退化,即经典的退化模型,是将HR图像依次进行模糊,下采样,加噪,JPEG压缩操作从而得到一个LR图像。公式如下:
D(.)表示退化过程,主要表现为HR数据(用y表示)先和模糊核做卷积使整个图像模糊,再下采样,然后加入噪声,最后做JPEG压缩。
Blur:高斯模糊核是常用的模糊退化核(尽管它可能并不能很好的模拟相机模糊),论文采用各项同性和各项异性高斯核,通过应用这些高斯核可以使生成器的输出图像更加锐利。
高斯模糊:取一个中心像素,给它周围的像素分配权重。距离中心越近,权重越高;越远,权重越低(符合高斯分布),然后将周围像素加权平均后赋值给中心像素。通过这种方式,高频信息像素值会被低频信息像素值拉低,从而表现高频信息不足,整体图像呈现模糊状态。
Noise:采用了两种噪声:加性高斯噪声和泊松噪声。加性高斯噪声的概率密度函数等于高斯分布的概率密度函数。泊松分布通常被用来逼近传感器噪声。
Resize(Downsample):从常用的采样算法(area、bilinear、bicubic)中随机选择操作,以产生不同风格的“模糊边缘”。
Nearest Neighbor (最近邻插值):新位置的像素点离原图哪个点最近,就直接抄哪个点的颜色。计算最快,但会产生严重的锯齿。因为它不进行任何加权平均,如果缩放倍数不是整数,像素点会产生微小的位移偏移(Pixel Shift)。这会导致生成的 LR 图和 HR 图在空间位置上对不齐,模型训练时会感到非常困惑。所以 Real-ESRGAN 倾向于避开它。
Area (区域插值):主要用于缩小图像。它会看新像素所覆盖的那个小区域,把区域内所有原像素的颜色值取平均。
Bilinear (双线性插值):它会找到新像素周围最近的 4 个点,根据距离远近进行加权平均。比最近邻平滑得多,但会丢失一些细节。
Bicubic (双三次插值):它会找到周围 16 个点 进行复杂的加权运算。它不仅考虑距离,还考虑了像素变化的斜率(三次方程)。它是超分辨率领域的“标准退化算法”。生成的图像边缘清晰度适中,最符合人眼视觉。JPEG:JPEG压缩在数字图像上应用较为广泛,表现则是当JPEG压缩因子大时,图像会有明显的块。JPEG的压缩因子取值范围为[0,100],值越小表示压缩力度越大,块状伪影越明显。
将上面四种操作组合起来,就得到了经典的退化模型。论文对经典的退化模型进行扩展得到高阶退化模型,高阶退化模型中的高阶表示的是多次经典退化模型。n阶退化模型就表示n次经典退化模型操作的组合。
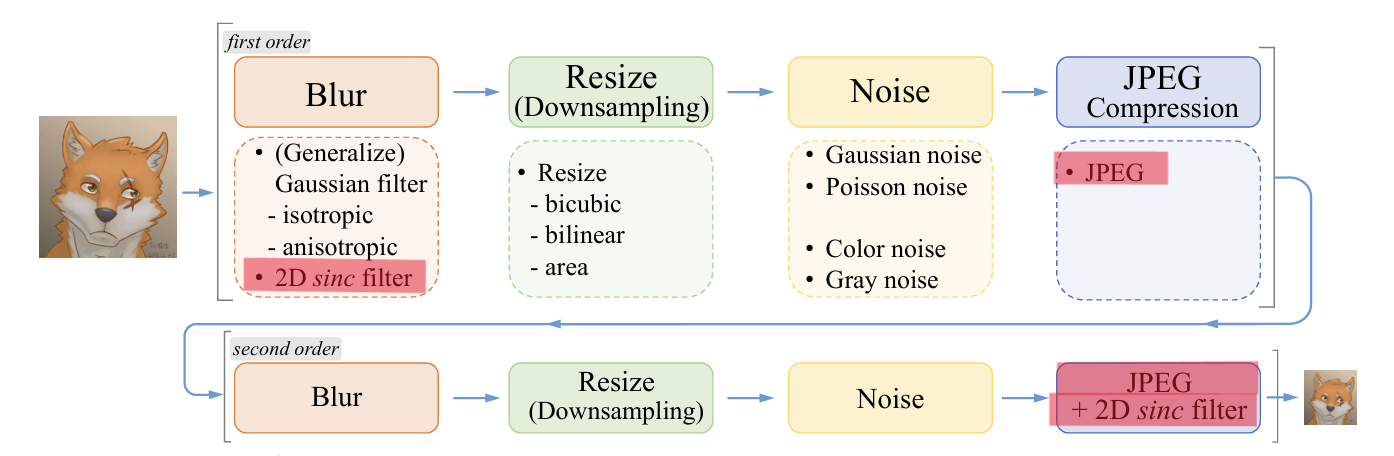
sinc filter
现实世界中的数字图像处理(比如缩放、JPEG压缩、锐化)并不是完美的数学运算,它们会引入一种副作用:振铃效应(Ringing Artifacts)。当你试图用有限的频率去模拟一个“极其锐利”的边缘(比如黑白交界处)时,由于高频信息被强行截断,边缘处就会产生像水波纹一样的震荡,视觉上它像是边缘附近的条纹或者鬼影。过冲伪影(overshoot artifacts)通常与振铃伪影相结合,表现为边缘过渡处增加的跳跃。
论文使用sinc filter来切断高频信息,通过调整 Sinc Filter 的截止频率(Cutoff Frequency),人为地在高清图的边缘制造出那种“重影”和“振铃”效果:
(i,j)表示filter核坐标,$\omega_c$是截止频率,$J_1$是第一类第一阶Bessel函数。通过调整 $\omega_c$,可以控制振铃效应的强弱,从而使生成的LR图像更接近真实世界中的退化图像。
模型在两个地方使用了sinc filter:一是在模糊操作的最后;二是在合成数据的最后一步设置sinc filter,我们知道合成图像的最后一步是JPEG压缩,为了涵盖更大退化空间,最后一步的sinc和JPEG的顺序是随机的,这是因为有的图像先做了锐化再进行JPEG压缩的,而有的图像是先做的JPEG压缩后进行的锐化。
加入sinc filter后的模型(一阶退化的JPEG压缩模块仍保留原来的设置,没有加sinc filter; 二阶退化的JPEG压缩模块加入了sinc filter(和jpeg的顺序随机))。
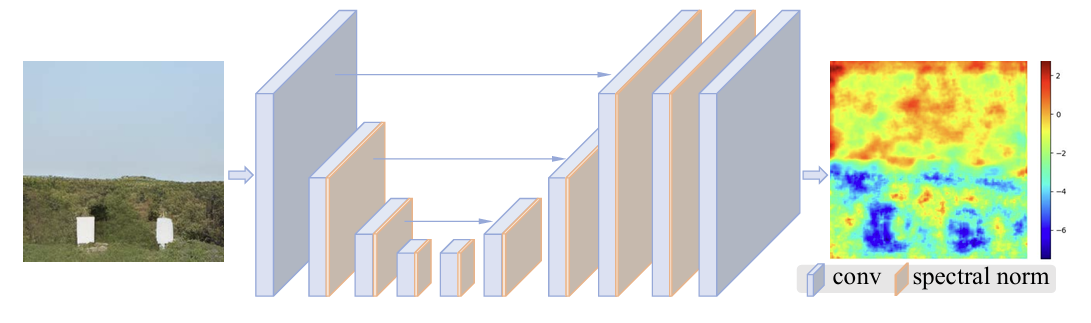
判别器的改动
由于退化变得更加复杂,因此模型的训练过程也更加不稳定,生成器的训练更加困难。Real-ESRGAN论文认为现在数据的退化空间更大了,原始的ESRGAN判别器不合适了,需要使用对复杂输入有更强能力的判别器,这个判别器可对局部纹理有更精确的梯度。论文使用了带有 Skip Connections 的U-Net结构。U-Net的输出是一个和输入图像尺寸一样大小的feature map,每一个像素都会和真实数值做比较回传梯度。
此外,由于U-Net和更复杂的退化都加大了训练的不稳定性,为缓解该问题,论文采用谱归一化SN(spectral normalization)正则项来约束判别器,将其网络参数的变动限制在一个范围内从而稳定判别器的训练,有效缓解了 GAN 在处理极其复杂的现实数据时容易出现的训练炸掉(不收敛)的问题。论文也发现,SN还有助于缓解gan产生的过锐和artifacts问题。

通过这些设置,论文实现了局部细节增强和artifacts压制的一种平衡。
生成器
Real-ESRGAN 的生成器基本沿用了 ESRGAN 的 RRDB(残差密集块)结构,但在输入端做了一个关键优化—Pixel Unshuffle,除了支持4倍超分还扩展到2倍和1倍超分。在x2和x1设置下,先采用pixel unshuffle来降低输入的空间尺度(扩大了通道数量)。将pixel unshuffle后的结果再送入ESRGAN网络中。这样可以减少GPU内存和计算机资源的消耗。
Pixel Unshuffle :想象一张原始图像,我们按一个 $r \times r$ 的小方格(比如 $2 \times 2$)对像素进行打散并重新排列.输入是一张分辨率为 $H \times W$,通道数为 $C$ 的图像。它把原本相邻的像素点“抽出来”,放进不同的通道里,例如,对于一个 $2 \times 2$ 的区域,它把左上、右上、左下、右下四个像素分别分给四个新通道。分辨率减小为 $\frac{H}{r} \times \frac{W}{r}$,但通道数增加为 $r^2 \times C$。
训练:
- 仍然采用两个阶段训练方法:先用L1 loss监督训练一个PNSR-oriented模型,该模型稳定后用作生成器的base模型,训练带gan的模型,损失采用L1 loss+ perceptual loss(即VGG loss) + Gan loss。
- 训练过程中sharpen GT:论文使用了一个trick,它对GT进行sharpen以使得label更加清晰,这个模型被称为Real-ESRTGAN+。实验确实表明了Real-ESRGAN+得到的结果更加sharpen,但也会引入一些过锐的artifacts,如振铃效应和过冲伪影。
- 引入exponential moving average(EMA),维护模型的一个影子权重,计算移动均值,减少训练的抖动,提升模型的稳定性和性能。
总结
这三个模型的演进是超分技术从“实验室数据”走向“现实复杂场景”的过程:SRGAN 首次引入 GAN 和感知损失,解决了传统 MSE 损失导致图像模糊的问题,让网络能生成高频纹理细节;ESRGAN 则对网络架构进行了大改(去掉 BN 层、引入 RRDB 密集残差块)并换用相对判别器,大幅减少了生成伪影,提升了画质和训练稳定性;Real-ESRGAN 直接沿用 ESRGAN 的核心网络结构,但重点攻克了训练数据生成问题,通过构建“二阶高阶退化模型”(反复叠加各种模糊核、噪声、Sinc 振铃和 JPEG 压缩),让模型学会了处理现实世界中真正残缺模糊的“烂图”。因此,SRGAN 是超分领域的开山之作,ESRGAN 则是对 SRGAN 的全面升级,而 Real-ESRGAN 则是将 ESRGAN 的能力真正落地到现实世界中的关键一步。