USRNet
论文:http://openaccess.thecvf.com/content_CVPR_2020/papers/Zhang_Deep_Unfolding_Network_for_Image_Super-Resolution_CVPR_2020_paper.pdf
参考:https://zhuanlan.zhihu.com/p/140507840
前言
图像超分模型的目标,就是将一张以某种方式退化的图像还原回原始图像。图像退化的过程是不可逆的,必然会损失一些像素级的信息(由此就引出了不同模型的不同优化目标,例如有的模型追求数学上更接近原始图,如PSNR,有的模型则追求感知上更接近原始图,如GAN)。一般而言,广义降质过程可以通过如下公式进行刻画:
其中$y$是退化图像,$x$是原始图像,$k$是卷积核(模糊核),$\otimes$表示卷积操作,$\downarrow_s$表示下采样操作,$n$表示噪声。根据模糊核k,噪声水平$\sigma$,与下采样操作s的已知与否,图像超分任务分为非盲超分(non-blind SR)与盲超分(blind SR)。非盲超分是指模糊核k,噪声水平$\sigma$,与下采样操作s都是已知的,而盲超分则是指至少有一个未知的情况。USRNet就是针对非盲超分任务提出的一种方法。
在USRNet之前,非盲超分模型大致分为两类:基于建模的方法和基于学习的方法。基于建模的方法(传统方法)在统一的MAP框架下处理不同尺度、模糊核以及噪声水平的图像超分,由于退化参数都是已知的,因此基于建模的方法通过数学寻优,尝试找到从LR到HR图像的转换流程(类似于图像退化的逆运算,尽管该过程是不可逆的),可看做是某种数学优化,由于该优化过程不依赖于退化参数的具体数值,因此具有较好的泛化能力,在各种退化条件下都能得到较好的结果,并且每一步的数学可解释性都很强,缺点是该方法是一个“在线优化”过程,每处理一张新图片,电脑都要从头开始解那个复杂的方程,因此计算效率非常差。基于学习的方法(深度学习方法/端到端方法)通过大量训练,直接发掘从LR到HR图像的某种深层规律,训练完成后,处理新图片只需要经过一次前向传播,就能立即得到HR图像,效率很高,是一个“离线学习”过程,缺点是模型只对训练集中的退化类型有效,灵活性和泛化能力较差,且模型的可解释性较差。
举个简单的例子,基于建模的方法就像是一个认真的学生,在拿到一道选择题时,他会从题目入手,一步步推导,演算,列方程,直到最终得到正确选项,这种方式很慢,但对于世界上的任何一道题目,都可以这样一点一点推导出最终的答案。而基于学习的方法就像是一个经验丰富的老教师,在拿到题目和对应选项后,他只需要对题中的数据略加计算(前向传播中的矩阵乘法),凭借自己多年的出题和教学经验(训练过程),就可以直接确定正确选项,而不用真的按照课本中的方法,循规蹈矩的一步步推导出答案,这样的方式速度很快,但是一旦换了一个国家或类型的题目(退化类型),他就不一定能“秒选”出正确选项了。
为解决上述问题,USRNet提出一种端到端可训练展开的网络,它集成了基于学习与基于建模的方法。
这里的“端到端”强调USRNet可以通过在最终图像层面进行比较并计算损失从而进行训练,“可训练展开”则表明USRNet将建模方法的数轮迭代在空间上展开成一个更深的网络结构,并且在每一层都引入了可学习的参数,从而使得USRNet能够通过训练来优化这些参数。具体来说,该模型通过half-quadratic splitting(半二次分裂,HQS)算法将MAP推理进展展开,通过固定次数的迭代求解数据子问题与先验子问题。上述两个子问题可以通过神经网络模块进行求解,从而得到一个可端到端训练的迭代网络。该网络从根本上将降质约束与先验约束信息嵌入到求解过程中,被证明兼具建模方法的灵活性泛化性和基于学习方法的高性能。
USRNet架构详解
从MAP到HQS
首先我们来了解一下MAP框架。MAP 的全称是 最大后现概率估计,它试图回答“在看到这张模糊低清图 $y$ 的情况下,哪张高清原图 $x$ 出现的概率最大?”。根据贝叶斯公式,MAP 将问题拆解为两部分:
其中数据保真项 (Data Fidelity)要求猜出来的 $x$ 必须符合物理退化模型(生成的 $y$ 要像真的)。先验项 (Prior)代表人类的“经验”,比如:我们知道真实世界的高清图边缘通常是锐利的、平滑的。这个项负责约束 $x$,不让它生出奇怪的噪点。USRNet的亮点之一,就是用神经网络替代了公式中难以定义的“先验项”,但保留了“数据保真项”的物理逻辑。
从MAP框架的角度来看,HR图像可以通过最小化如下目标函数进行估计:
这里加入噪声强度超参数$\sigma$,是为了将目标函数的第一项归一化到相同的尺度进行计算,让模型能够适应不同噪声水平的图像。
为得到上述公式的展开推理,作者选择了半二次拆分(half-quadratic spliting, HQS)算法(因其简洁性与快速收敛性)。HQS通过引入辅助变量z对上述公式进行求解,从而有如下等价近似关系:
其中$\mu$为惩罚性参数,控制着辅助变量z与原始变量x之间的关系。
由于在 MAP 框架下,我们要最小化:$|y - Hx|^2 + \lambda \Phi(x)$,其中第一项是一系列复杂的包含模糊和下采样的物理操作,第二项是一个难以明确定义的先验项,物理退化(保真项)通常可以用线性代数求解,而图像先验(正则项)在深度学习中是一个极其复杂的非线性神经网络,这两项通过x被耦合在一起,方程根本解不出来,也无法计算梯度。因此HQS通过引入辅助变量 $z$(可以把 $z$ 看作是 $x$ 的一个临时复印件),我们把原来的一个大问题强行劈成了两个互不干扰的小问题:让替身 $z$ 去专门对付物理退化(只考虑模糊和下采样),让本体 $x$ 去专门对付图像先验(只考虑去噪和变清晰),这样就实现了两个复杂函数优化的解耦。
那么这样做能保证我们得到最终想要的x吗?正确性的绝对保障在于那个惩罚参数 $\mu$ (Penalty Parameter),以及公式最后面的惩罚项 $\frac{\mu}{2}|z - x|^2$。在传统的 HQS 算法迭代中,$\mu$ 不是一个死数字,而是一个随着迭代次数逐渐增大的值:刚开始迭代时,$\mu$ 很小,替身 $z$ 和本体 $x$ 可以各自优化,差距很大;随着迭代深入,$\mu$ 变得越来越大(趋近于无穷大)。为了让整体的能量函数 $E_\mu(x, z)$ 保持最小,算法会被强迫让 $|z - x|^2$ 趋近于 0。当 $\mu \to \infty$ 时,$z$ 必须等于 $x$,此时,近似公式 $E_\mu(x, z)$ 就完全等价于原始目标公式 $E(x)$。
在纯数学算法里,$\mu$ 是人工设定的一组递增序列;但在 USRNet 中,每一层迭代(Stage)的惩罚参数(包括步长)都是作为神经网络的可学习参数(Learnable Parameters),通过端到端的训练让机器自己去找到最优的收敛节奏,这进一步提升了速度与准确度。
用$E_\mu(x, z)$近似$E(x)$后,我们就可以通过迭代交替优化(Alternating Optimization)x与z来求解这个问题了:
可以看到,数据项与先验项可以进行解耦。对于数据项而言,可以采用快速傅里叶变换进行求解;对于先验项而言,它等价于降噪问题,可以用其它降噪模型进行解决。
Deep unfolding Network
既然确定了这种迭代交替优化的策略,下一步的任务就是如何设计一种有效的展开超分网络。由于展开优化主要包含迭代优化数据子问题与先验子问题,USRNet需要在数据模块与先验模块之间进行交替执行。此外,模型中将数据项的$\mu \sigma^2$用超参数$\alpha_k$替代,将先验项的$\lambda$和$\mu$用超参数$\beta_k$替代,都是用于衡量公式中两项的相对重视程度。子问题的求解就需要将$\alpha_k$和$\beta_k$也纳入输出中。为了找到这样一组合适的$\alpha_k$和$\beta_k$,USRNet引入了一个超参数模块$\mathcal{H}$,该模块以退化参数(如模糊核k,噪声水平$\sigma$,下采样操作s)作为输入,输出每一层迭代的$\alpha_k$和$\beta_k$。通过训练,模型能够学习到在不同退化条件下,如何调整数据项与先验项中的权重,从而实现更好的超分效果。在论文中,作者设置总迭代轮数(即数据项-先验项层数)K=8.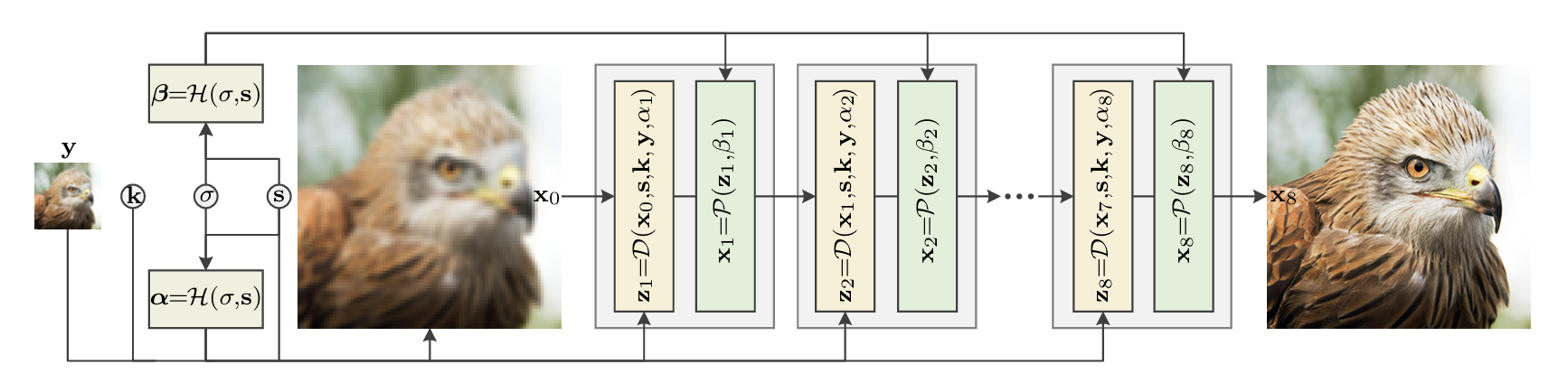
数据模块D
数据模块的目的在于最小化数据项$|y - (z \otimes k)\downarrow_s |^2$与正则项$|z - x_{k-1}|^2$,二者以权衡因子$\alpha_k$进行加权求和。由于数据项与图像退化相关,故该数据模块应该考虑尺度因子,模糊核,LR图像作为输入。此时,该优化问题可以简写为:
- $x_0$通过最近邻插值初始化。上述公式实际上继承了建模方法,并未包含需要训练学习的参数,故而具有更好的泛化性能。在实现过程中,上述公式具有封闭解,可以通过快速傅里叶变换进行求解。
先验模块P
先验模块的目的在于对前述得到的$z_k$进行降噪得到清晰的HR图像$x_k$,受FFDNet启发,作者提出一种包含噪声水平$\beta_k$作为输入的深度去噪方案:
这里的$\beta_k$是均衡因子,也可以看做噪声水平,因为噪声越强烈的图片,越需要增大降噪项的权重
USRNet所提出的去噪方法称之为ResUNet,它集成嵌入残差模块到UNet中,以$z_k$和噪声水平$\beta_k$作为输入,输出降噪后图像$x_k$。ResUNet可以通过单个模型处理不同噪声水平的降噪问题,这极大的降低了总参数量。
超参数模块H
超参数模块起滑动条的作用去控制数据模块和先验模块,比如使得$z_k$随$\alpha_k$的增加而逐渐逼近$x_k$。按照定义,$\alpha_{k}$ 由 $\sigma, \mu_{k}$ 决定,而 $\beta_{k}$ 由 $\lambda, \mu_{k}$ 决定。那么该超参数模块可以描述为:
超参数模块也是一个神经网络,包含三个全连接层,前两个后接ReLU,最后一个后接Softplus,隐含层的通道数为64。
物理意义上,$\alpha$ 和 $\beta$ 依然可以看做是噪声、先验和惩罚项的某种组合。但它们不再是像原公式里的那样将计算逻辑写死,而是通过超参数模块灵活调整。
端到端训练
在训练时,作者首先选用L1损失训练以达到最佳PSNR性能,然后采用L1损失、感知损失以及对抗损失(三者权值因子为1,1,0.005)微调一个具有最佳视觉效果的模型,此时所得模型称之为USRGAN。
L1损失指生成图像与真实HR图像的像素级绝对距离,感知损失指生成图像与真实HR图像在某些特征空间(如VGG网络的某些层)的差异,对抗损失则是通过一个判别器来评估生成图像的真实性,从而引导生成器生成更逼真的图像。因此,需要引入一个GAN结构。原始的USRNet不含有GAN结构,因此只使用L1损失。
- 在我第一次学到这里时,产生了一个疑问:上面明明说了模型是根据MAP的$E(x)$损失设计的,也基于这个损失提出了一系列设计(如HQS),为什么在训练时又变成使用L1损失、感知损失和对抗损失了呢?
其实这并不矛盾,MAP的$E(x)$损失是用来指导模型架构设计的,从HQS算法,到模型超参数模块,数据模块和先验模块的解耦以及多层迭代的设计,本质上都是在模拟MAP的HQS优化过程,也就是说,当数据在模型中前向传播时,该数据实际上就是在做MAP的优化过程,从而得到在MAP框架下高质量的HR图像。而L1损失、感知损失和对抗损失则是用于训练模型本身的参数的,使其能够更好地拟合数据并生成高质量的图像。可以这么说,USRNet本身是一台机床,该机床将送入的原材料加工成符合MAP标准的成品,那么机床自身应该怎么设计制造呢?答案就是使用上面的L1损失+感知损失+对抗损失来训练这个机床,调整机床的参数,从而得到一个能够生产出符合MAP标准的成品的机床。
那为什么不直接使用MAP的$E(x)$损失来训练模型呢?
因为先验项$\Phi(x)$是一个难以明确定义的函数,很大程度上依赖于人的主观,并且这么做会大大增加训练的复杂度和难度。
既然这样,我为什么不可以使用一个预训练的,参数固定的神经网络,专门用来衡量$\Phi(x)$,即先验损失,然后把这个网络接入USRNet进行训练呢?
- 实际上的确存在这样的分支,叫做即插即用(Plug-and-Play, PnP)方法,并且这种“专门用来衡量$\Phi(x)$的网络”的思想,涉及到基于能量的模型(Energy-Based Models, EBM)和生成式先验(Generative Priors)等领域的研究。但这么做有几个缺点:1. 优化过程极慢;2. “对抗性攻击”风险(找到伪影解),神经网络定义的能量函数 $\Phi(x)$ 通常是不完美的,如果强行在 MAP 上优化这个能量函数,算法非常容易找到一些“分值极低但视觉极烂”的病态解;3. 训练的“二阶稳定性”问题,训练难度大,不够稳定,且对显存要求高。
- 以上答案为Gemini生成,实际上我觉得这些都不是致命的缺陷,而且这种训练方式在某种程度上与扩散模型的思想不谋而合,可能是某个潜在的研究方向,即Diffusion+SR。
总结
该方法将退化模型与先验信息约束到解空间中,从而具有更好的性能与泛化能力。通过集成建模方法与学习方法的优势,实现了单模型处理多种图像退化问题,是一种非常有创新性的图像超分方法。