Flow matching 与 Rectified flow
Rectified flow:
原作者的博文
另一篇对Rectified flow的解读,个人认为视角非常高,暂时没完全理解
论文:Flow Matching for Generative Modeling
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Occam’s razor:Entities must not be multiplied beyond necessity
前言
我们知道,图像生成模型的根本目的在于找到一个从先验分布到数据分布到映射。在现实世界中,我们只有真实数据和纯噪声,而看不到从噪声到数据的中间过渡过程,那么,我们的模型就需要建模这个过程,使得在这样的过程假设下(注意,这里说的是“假设”,因为根本不存在一个“客观正确”的转换过程),模型能够产生一个与数据分布尽可能接近的分布。Flow matching实际上提出了一种高度抽象化概括性的过渡假设:它借鉴了物理学中连续性方程的概念,概率分布就像一个凹凸不平的曲面(高维空间中应该是凹凸不平的流形),这个曲面由大量的流体粒子构成,流体会随时间发生流动迁移,那么该曲面(分布)也会逐渐变化,这种概率(分布)的“流动”就叫做概率流。为什么说这种假设是高度抽象化概括性的呢?因为它不依赖任何特殊的前提或性质(如DDPM就依赖Markov性质),只是简单的刻画概率分布的连续转移过程,限制条件只有两条:1,变化是连续的,这个非常合理,也更好处理;2,“流体”总量是守恒的,这个不用说,毕竟概率之和恒为一。这种极简的假设,为该模型带来了很好的通用性与生成效果,并且在实践层面的处理过程也非常简单。
预备知识
物理学中的连续性方程:
其中$\rho$是概率密度,$\partial \rho (\mathrm{x}, t) / \partial t$是概率密度随时间的变化率,$\nabla \mathrm{j} (\mathrm{x}, t)$是概率流的散度,表示概率流的发散程度,衡量从点周围一个无穷小体积元中净流出的概率流的强度。散度大于0,说明概率流从该点流出,该点的概率密度在减少;散度小于0,说明概率流流入该点,该点的概率密度在增加;散度等于0,说明该点的概率密度保持不变。
概率路径与流映射
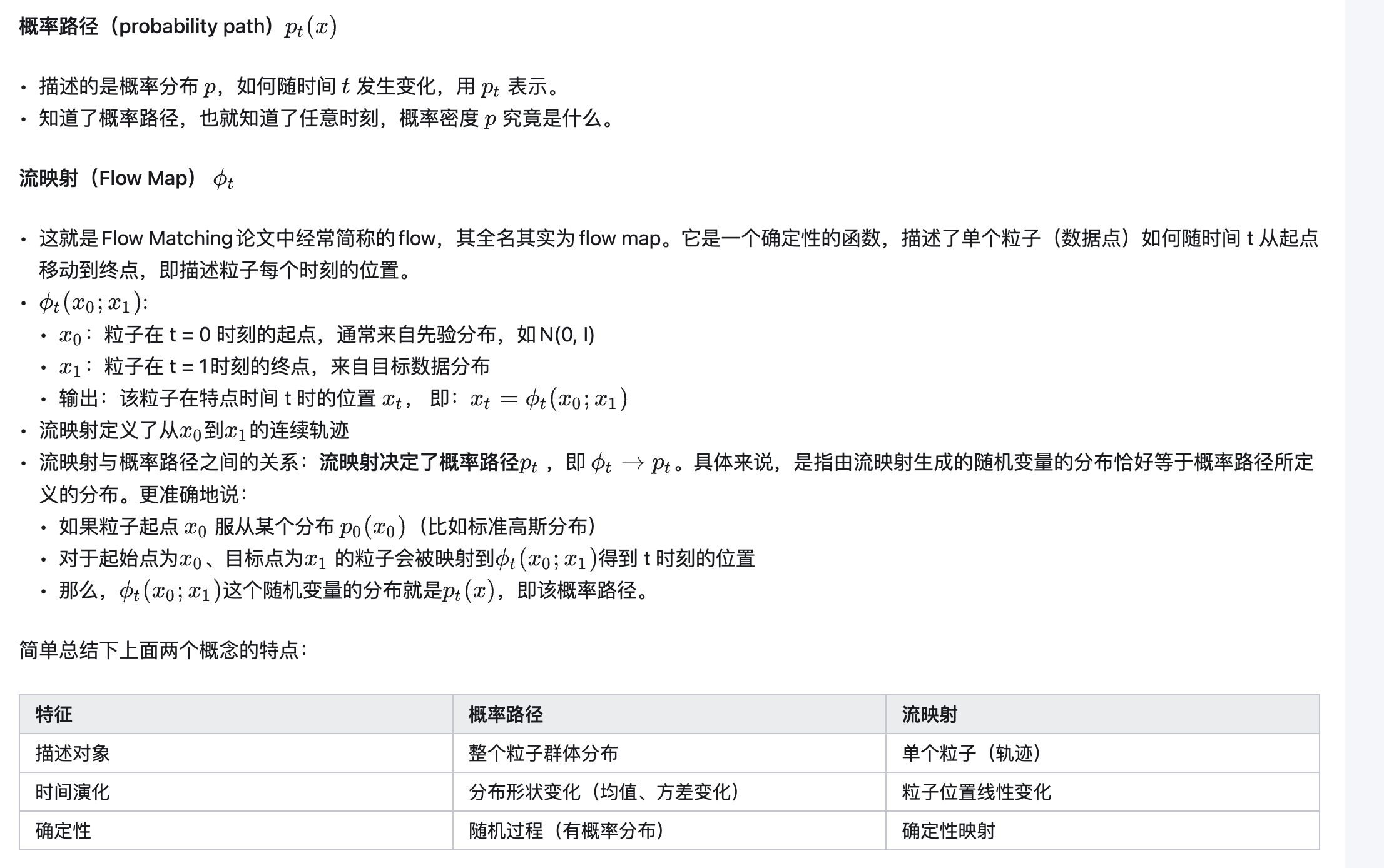
Normalizing Flow & Continuous Normalizing Flow



Flow matching


注意,这里的速度场$u_t(x)$并不是真实存在或可测量的,而是我们假设出来的,或者说“我们认为粒子实际上应该怎么运动”。后续可以看到,我们通过假设的条件分布$p_t(x|x_1)$或flow map$\psi_t(x;x_1)$,可以通过求解连续性方程来推出对应的速度场$u_t(x)$。
现在的问题是,我们并不知道这个参考速度场$u_t(x)$和这群粒子的概率路径$p_t(x)$,因此上述目标其实并不可行。下面,我们来解决$u_t(x)$和$p_t(x)$的untractable问题。
条件概率路径的平均可以近似边缘概率路径
给定一个真实数据分布中的样本$x_1$,我们可以通过条件概率分布的混合来构建我们想要的目标概率路径,即:
这个条件概率分布 $p_t(x|x_1)$ 也是一个概率路径,它的含义是:在终点为 $x_1$ 的前提下粒子的概率路径。并且,这个概率路径需要符合两个条件:第一,在 $t=0$ 时刻 $p_0(x|x_1)=p(x)$,即初始时刻服从简单分布;第二,作者们设计在 $t=1$ 时刻,$p_1(x|x_1)=\mathcal{N}(x|x_1, \sigma_{min}^2 I)$,并且 $\sigma_{min}$ 足够小,这个条件的含义是 $t=1$ 时刻,粒子应该聚集在终点 $x_1$ 附近,服从以 $x_1$ 为均值的高斯分布。如何理解这两个条件呢?首先,第一个条件保证了,所有那些最终能够生成$x_1$的粒子,在初始时刻都是随机分布的,真实数据样本并不偏好先验分布中某一区域的粒子,先验分布中的每一个粒子都有同样的机会成为生成$x_1$的粒子;第二个条件保证了在$t=1$时刻,所有能够生成$x_1$的粒子都聚集在$x_1$附近很小的一个区域内,这么做的动机是显然的,因为这个条件概率路径的条件就是假设终点是$x_1$。
这样,我就可以多次采样$x_1$,每次采样得到一个条件概率路径$p_t(x|x_1)$,这些条件概率路径的平均就近似了我们想要的边缘概率路径$p_t(x)$了。
条件速度与边缘速度在优化效果上是等价的
针对$u_t(x)$的untractable问题,首先,推导出
代入原始loss:
再通过方差-偏差分解,得到
所以我们可以直接优化左边那项来间接达到优化原始目标函数的效果。因此,作者们提出使用左边这项作为Conditional Flow Matching(CFM)的目标函数进行优化:
构造概率路径
现在,观察我们的目标函数$\mathcal{L}_{CFM}(\theta)$,可以看到,其中的$t$,$x_1\sim q$可以通过采样得到,$v_t(x)$是通过神经网络学习得到,而条件概率路径$p_t(x|x_1)$和条件速度场$u_t(x|x_1)$依然是未知的。实际上,这两个未知量具有天然的联系:粒子在速度场的“推动”下演化出了概率路径。有了概率路径,我们就可以反推出速度场。因此,我们先设法构造出这个概率路径。Flow matching中,作者将其设计成了一种高斯概率路径:
其均值和方差都是关于时间$t$和终点$x_1$的函数。由于上面所写的对概率路径的两个条件,我们可以得到:
那么现在的问题就是设计这两个函数了。实际上,满足这种条件的函数有无数种,作者们在论文中给出了两种选择:
- Diffusion路径:
其中,$\alpha_t = e^{-\frac{1}{2}T(t)}$, $T(t) = \int_0^t \beta(s)\mathrm{d}s$,这里的 $\beta(s)$ 就是 diffusion 论文中提到的 noise scale function。
- Optimal Transport (OT)路径:这个路径是形式最简单的,均值和方差的函数在二维平面上看就是连接起点和终点的一条直线
现在我们有了条件概率路径$p_t(x|x_1)$,但在实践中,我们并不会直接从这个条件概率路径中采样,而是对目标函数进行进一步优化:
首先,根据$p_t(x|x_1)$,我们可以推出各个粒子的flow map:
为什么flow map是这个形式:注意到假如初始分布为$x_0 \sim \mathcal{N}(0, I)$,则将$x_t$代入上面的flow map,根据正态分布的性质,条件概率路径就刚好是我们上面定义的$p_t(x|x_1)$。说的更规范一点,将flow map作用于先验分布,就可以得到条件分布路径。这个Push-forward过程在原论文中有更详细的描述,可以参考原论文。
那么我们就可以得到,对于任意可积函数f,都有:
也就是说,从某个中间时刻t采样,就等价于先从初始时刻采样,然后通过flow map把采样点“推”至中间时刻t。
这样,就可以化简我们之前找到的CFM loss:
这个化简后的 CFM loss 使得我们可以从初始分布 $p(x_0)$ 采样来替代从 $p_t(x|x_1)$ 中采样,更为简单。
速度场可由CNF的ODE推出
接下来,我们还有最后一个问题:$\mathcal{L}_{CFM}(\theta)$中的条件速度场$u_t(x|x_1)$是未知的。实际上,由于我们的flow map是在速度场的“推动下”产生的轨迹,因此自然可以用flow map推出速度场。联系它们的等式是CNF的ODE:
代入
解得
这样我们就顺利构建了想要的条件速度场 $u_t(x|x_1)$。
对于我们之前提到的两种路径,其条件速度场形式分别为:
Diffusion路径:
OT路径:
实践中,由于 OT 路径更为简单,因此采取第二种形式进行优化:
最终我们得到了实践中常用的 CFM 目标函数:
现在,我们得到了所需的所有组件。以下为训练过程:
- 首先,从数据分布 $q(x_1)$ 中采样一个数据样本 $x_1$ 作为终点,从初始分布 $p(x_0)$ 中采样起点样本 $x_0$,从均匀分布采样时间 $t \sim \mathcal{U}(0, 1)$;
- 计算给定的 flow map 来构造中间状态点:
- 将中间状态点 $\psi_t(x_0)$ 输入模型 $v_t(\cdot; \theta)$,得到预测速度场输出;
- 计算目标速度场:
- 计算最终的均方误差损失:
通过反向传播优化参数 $\theta$,使模型逐渐学会逼近真实向量场。
关于Flow matching的一些insight
- 我们希望模型学到的是边缘速度场$u_t(x)$,但模型实际上学到的是“平均条件速度场”$E_{x_1\sim q}u_t(x|x_1)$,从统计上讲,只要参与训练的样本够多,模型学到的“平均条件速度”和“边缘速度”是相等的。但是这样有个问题:由于每次在数据分布中的采样的真实图都是不确定的,从先验分布采样的噪声也是随机的,模型往往会学到不同速度的平均,最终导致中庸的结果,影响成像质量。
- 关于条件分布:首先想象我们有一大群随机的粒子(先验分布),这一大群粒子逐渐过渡到了某种特殊的形状(数据分布)。在给定$x_1$下,得到的条件概率路径,或条件速度场,就相当于我们选取了最终数据分布的某一小片区域(实际上是某一个数据点),然后观察:在起初的一大批随机粒子中,有哪些粒子是最终移动到这个选定的数据点的?然后只保留这些数据点,把其他的数据点忽略。这样,这些数据点的概率路径就是条件概率路径,其中每一个粒子都是径直走向$x_1$的,并且由于这些点的起始位置互不相同,而且它们都是走直线,所以路径不会相交。但是,如果考虑数据分布的所有点,那么在同一个位置可能就有多个速度,最终模型学到的速度是所有这些速度的叠加。在条件速度场中,如果在t=0时刻向速度场中放一个粒子,它会走直线到$x_1$,但如果是叠加的速度场,则该粒子大概率是走曲线,因为不能保证叠加后的速度场仍然是恒定(x1-x0)的。
- 通过一系列推导,我们发现最终的条件速度场是个定值x1-x0,很多人对Flow matching的印象也是“直接预测噪声图与真实图的差异”。值得注意的是,无论是“速度为定值”还是“轨迹(即flow map)为直线”,都指的是在给定了x1作为条件的情况下,而实际的边缘速度是各个条件速度的加权,大概率不是定值,那么实际的轨迹也大概率是一条曲线,尽管拟合目标是所谓的直线,但实际边缘分布或者推动边缘分布的速度场,仍然是曲线,所以才有类似2-reflow或者OT-CFM等工作出来,尽可能将曲线拉直。曲线轨迹有什么问题呢?我们在实际生成图片时,是不知道真实图像x1的,也就不存在条件速度场,我们能使用的,有且只有边缘速度场,而边缘速度场产生的轨迹是曲线,这就导致求解ODE时,每一步不能走的太大,必须一点一点严格按照曲线的轨迹前进,才能到达数据分布,如果步长太大,很容易脱离轨迹,甚至进入流形的“涡流区”,得到完全错误的数据分布。简单来说,曲线边缘速度场会大大影响生成效率的生成质量,而如果边缘速度场也是定值(直线),就可以以更少的步数生成更好的图片。
- 为什么会产生曲线的边缘速度场?想象一下,在高维空间中,由于每次对x0和x1的采样都是随机的,假如第一次采集到了左下角的x0和右上角的x1,那么模型想要预测的速度是指向右上方的;而第二次采集到了右下角的x0和左上角的x1,那么模型想要预测的速度是指向左上方的。这样多次采样的轨迹发生了交叉,模型预测的速度也被迫进行了平均—指向正上方,然而正上方什么也没有。因此我们希望尽量避免轨迹的交叉,一个解决办法就是在采样时就选取距离最近的一对(x0,x1),这样两两搭配,可以一定程度避免交叉,这正是OT-CFM的思路。
- 既然很多情况下曲线是由于样本配对的随机性导致的,那么消解的方法其实也很直观,就是尽可能减少传输距离,使得某一些分布能固定传输到离它最近的分布里,从实操上看大体有两种方法:(1) 通过reflow论文里提到的方式,因为我们看到虽然路径是曲线,但训练好的模型能自动帮训练样本找到最有传输路径对应的分布,所以通过pretrain好的flow模型进行再次采样得到训练集,再训练一个flow模型,以此往复n次,那么理论上讲得到的路径会越来越直,但也会因为逐渐累积误差导致性能下降;(2) 对于训练样本,直接对传输距离进行优化,那么就能尽可能避免路径交叉的问题;无论是对于(1)还是对于(2),我们应当充分认识到,现实中的数据分布是相当复杂的,光靠简单的方法仍然是很难实现所谓的“走直线”的目标的;
- 既然“条件轨迹”可能交叉,那为什么最终的“边缘轨迹”却不会交叉?可以参考物理中的磁感线—因为叠加后的速度方向是唯一的。
- 在第1点中,一方面,只要训练样本足够多,那么条件速度场的平均就无限接近边缘速度场,这与我们的训练目标一致;另一方面,过多样本对(x0,x1)的叠加,会导致模型学到一个过于平均中立的速度场,这反而对生成不利。怎么理解这个矛盾?—首先,在现实世界中,我们有的只是先验分布和数据分布,实际上压根就不存在某种“客观正确”的演变过程,或者“绝对准确”的速度场,虽然我们试图用神经网络来拟合“真实”速度场u,但实际上,这个所谓的“真实速度”u却是由我们对概率流$\psi$的假设来构造出来的。也就是说,“统计上的正确”并不意味着这一结果对我们是有利的,因为我们的拟合目标很可能就是一个极度扭曲震荡的速度场。换句话说,既然这里的“真实速度场”是我们自己构造出来的,那么我们就要构造出一个对后续的图像生成最有利的速度场,也就是OT的”直线速度场“。如果我们不使用OT-CFM,可能构造出一个扭曲的速度场,在理论上,当我们的时间步采样足够密集,即求解ODE时采用的步长足够小,也能在这个速度场的引导下走到数据分布,生成合理的图片。但是,我们的时间有限,也不可能做到“无限密”采样,所以直线的边缘概率路径是更有利的:理论上讲,边缘概率路径是不是直线都一样,但实践中,直线更好。
Rectified flow
在上面的介绍中,我们了解到:
- Flow matching的条件轨迹/点源场是直线的,而边缘轨迹/叠加场是曲线的。造成叠加场是曲线的原因是:对于同一时刻同一位置$x_t$,在训练过程的多次采样中可能由不同的噪声-图像组合(x0,x1)产生,既然这些(x0,x1)组合不同,那么同样对于$x_t$,速度方向就不同,条件轨迹发生交叉,模型要学习到的目标也不同,所以模型被迫只能学到两个速度的平均,这与每条路线之前(小于t)与之后(大于t)模型学到的速度不一样,这种速度的震荡就导致了边缘轨迹的曲线化。
- ODE叠加场中的速度场在每一点都是唯一的,都等于叠加后的速度,也就是说边缘概率轨迹不会相交。
如果粒子的运动轨迹是弯曲的,我们需要很细的离散化来得到很好的结果。如果粒子的轨迹是直线,那么即使我们取最大的步长,只用一步走到t=1时刻, 还是能得到正确的结果。 所以,我们希望我们学习出来的速度模型$v_\theta$既能保证$x_0$到$x_1$的正确转换, 又能给出尽量直的轨迹。
Rectified flow的核心思想就是在Flow matching的基础上,通过优化样本配对的方式,来尽可能减少路径交叉,拉直边缘轨迹。简单来讲rectified flow就是先随机从先验分布和数据分布中采样,训练出一个初始的1-rectified flow模型,然后再从先验分布中采样,并把样本送入1-Rectified Flow得到对应的数据点集${x_1}$,拿这样的先验-数据样本对(x0,x1)训练下一个2-retified flow模型,以此类推。
Rectified flow的核心在于其reflow方法,具体的做法非常简单:假设我们从 $\pi_0$ 里采样出一批 $X_0$。然后,从 $X_0$ 出发,我们模拟上一次的模型学出的 flow(叫它 1-Rectified Flow),得到 $X_1 = \mathrm{Flow}_1(X_0)$。我们用这样得到的 $(X_0, X_1)$ 对来学一个新的 “2-Rectified Flow”:
这里,2-Rectified Flow和1-Rectified Flow在训练过程中唯一的区别就是数据配对不同:在1-Rectified Flow中,$X_0$ 与 $X_1$ 是随机或者任意配对的;在2-Rectified Flow中,$X_0$ 与 $X_1$ 是通过 1-Rectified Flow 配对的。因为从 1-Rectified Flow 里出来的 $(X_0, X_1)$ 已经有很好的配对,他们的直线插值交叉数减少,所以 2-Rectified Flow 的轨迹也就(比起 1-Rectified Flow)变得很直了(虽然仔细看还不完美)。理论上,我们可以重复 Reflow 多次,从而得到 3-Rectified Flow, 4-Rectified Flow… 我们可以证明这个过程其实是在单调地减小最优传输理论中的传输代价(transport cost),而且最终收敛到完全直的状态。当然,实际中,因为每次 $v$ 优化得不完美,多次 Reflow 会积累误差,所以不建议做太多次的 Reflow。幸运的是,在实验中,我们发现对生成图片和很多我们感兴趣的问题而言,1 次 Reflow 已经可以得到非常直的轨迹了,配合蒸馏足够达到一步生成的效果了。
蒸馏模型
给定一个配对 $(X_0, X_1)$,要想实现一步生成,也就是 $X_1 \approx X_0 + v(X_0, 0)$,我们好像也可以通过优化下面的平方误差来直接 “蒸馏 (distillation)” 出一个一步模型:
由于X0和X1的关系很复杂,直接训练蒸馏模型很难取得好的效果。而Reflow和Distillation可以组合使用:先用Reflow得到比较好的配对,最后再用已经很好的配对进行Distillation 。作者在论文里发现,这个结合的策略确实有用。
为什么能行?
不难想象,为了尽可能条件概率轨迹交叉,我们应该让每个先验样本x0都与距离它最近的数据样本x1配对,从物理学的角度看,这样的传输(配对)是最经济的,需要或损耗的能量最小,也是最容易满足的传输方式。那么,为什么将先验分布的粒子送入1-rectified flow,就能在1-rectified flow的速度场的引导下,转移到距离自己最近的数据样本点呢?在上面我们提到,由这个速度场生成的 ODE 轨迹在空间中是不可能相交的,既然路线不会交叉,那么每一个粒子就都只能前往离自己最近的终点,如果左边的粒子想去右边,右边的粒子想去左边,就必然会引起路线交叉!从数学上讲,一个不相交的映射(Non-crossing map),在几何空间上天然就极其逼近最优传输(Optimal Transport, 就近分配)。所以,在不相交的边缘轨迹下,粒子天然就会前往离自己最近的位于数据分布中的点。
rectified flow的理论保证
- 边际分布不变:当 $v$ 取得最优值时,对任意时间 $t$,我们有 $Z_t$ 和 $X_t$ 的分布相等。因为 $X_0 \sim \pi_0, X_1 \sim \pi_1$,因此 $Z$ 确实可以将 $\pi_0$ 转移到 $\pi_1$。
- 降低传输损失:每次 Reflow 都可以降低两个分布之间的传输代价。特别的,Reflow 并不优化一个特定的损失函数,而是同时优化所有的凸损失函数。
- 拉直 ODE 轨迹:通过不停重复 Reflow,ODE 轨迹的直线性(Straightness)以 $O(1/k)$ 的速率下降,这里,$k$ 是 reflow 的次数。
补充
理论上来说,2-Rectified只能加速生成,但生成效果是要小于等于1-Rectified的。所以整个Rectified Flow的流程是,第一次训练拟合与插值边缘分布一致的ODE,得到生成模型,无法一步采样;第二次训练拟合插值的速度,贴近插值方程(直线),实现一步采样。并且,reflow的思想也可以应用至其他diffusion模型而不是局限于flow matching。最后,rectified flow不局限于高斯分布向数据分布的转换,而是可以在任意两个分布之间转换,能够对一般分布的变化进行一步生成,这也拓展了其在风格迁移,图像修复等领域的应用。