Mean Flow
参考:https://zhuanlan.zhihu.com/p/1908857108243407231
https://www.zhihu.com/question/1982041752169910918/answer/1982042548311700867
原论文:https://arxiv.org/abs/2512.02012
Mean Flow简述
Mean Flow的核心思路在于,它不再像flow matching那样通过让模型预测条件瞬时速度的期望从而预测边缘瞬时速度v,而是通过让模型学习预测边缘平均速度u。
通过推导,得到以下边缘平均速度的表达式MeanFlow 恒等式(MeanFlow Identity):
值得注意的是,我们是从平均边缘速度推出的这个等式,但实际上,只要u满足这个等式,也可以证明这个u就是边缘平均速度。也就是说,这个等式是充要条件,这对于下面优化合理性的理解非常重要。
我们的目标就是让模型输出$u_\theta(z_t, r, t)$逼近真实的$u(z_t, r, t)$:
但是有个问题,$u(z_t, r, t)$的计算需要知道真实边缘瞬时速度$v(z_t, t)$和u关于t的导数$\frac{d}{dt} u(z_t, r, t)$,而这两者都是未知的:我们只知道真实条件瞬时速度。也就是说,标签u的计算依赖于它自身的导数,这就形成了一个隐式方程。为了解决这个问题,Mean Flow做了以下近似:首先,借鉴FM的思路,由于匹配条件速度的期望(即边际瞬时速度)是可行的,因此在每一轮训练时用条件瞬时速度(OT中,该条件速度是定值noise - data)来代替边缘瞬时速度;其次,用模型输出关于t的数值导数,即$\frac{\partial u_\theta}{\partial t}$来近似u关于t的导数。这样就得到了一个可计算的标签:
在计算$\frac{\partial u_\theta}{\partial t}$项时,需要用到雅可比 - 向量积(JVP)。
注意,在近似后,模型的预测目标仍然是边缘平均速度,而不是条件边缘速度(条件边缘速度为定值noise - data)。仅仅是在训练时用条件瞬时速度来近似边缘瞬时速度,在期望意义下,效果与用真实的边缘瞬时速度是一样的。
训练
- 从数据分布和噪声分布中采样 $x$ 和 $\epsilon$。
- 根据预设的轨迹函数(如直线路径),基于 $x$ 和 $\epsilon$ 计算中间状态 $z_t$ 和条件瞬时速度 $v_t$。
- 采样一对时间步 $(r,t)$,通常 $0 \le r < t \le 1$。
- 调用网络 $u_\theta$ 计算其在 $(z_t,r,t)$ 处的预测 $u_\theta(z_t,r,t)$。
- 使用 JVP 计算 $\frac{d}{dt}u_\theta(z_t,r,t)$。
- 构建目标 $u_{tgt} = v_t - (t - r)\mathrm{sg}(\frac{d}{dt}u_\theta(z_t,r,t))$。
- 计算损失 $\mathcal{L} = ||u_\theta(z_t,r,t) - u_{tgt}||^2$ (可能使用加权)。
- 反向传播计算损失对 $\theta$ 的梯度,更新网络参数。
推理
- 从先验分布采样噪声 $z_1$。
- 调用训练好的网络计算 $u_\theta(z_1, 0, 1)$。
- 计算生成的样本 $z_0 = z_1 - u_\theta(z_1, 0, 1)$。
MF的优势在于,它可以一步生成高质量的图片,极大地缩小了高性能多步生成模型与高效一步生成模型之间的差距,并且可以自然融入CFG的生成效果。
一些问题
- Mean Flow实际上做了两种近似,一个是用条件瞬时速度来近似边缘瞬时速度,另一个是用模型输出的数值导数来近似u关于t的导数。这两种近似的合理性是什么?为什么它们在实践中能够得到好的结果?
- 首先,关于用条件瞬时速度来近似边缘瞬时速度,这个近似的合理性可以从期望的角度来理解,在flow matching中就使用了这样的思路并作了解释,只要训练样本足够多,每一轮都用$v_{cond}$的效果与用$v_{marg}$的效果是一样的。其次,关于能否用模型输出的数值导数来近似u关于t的导数,实际上,只要优化的足够充分,可以认为loss是0,那么就满足$u_\theta(z_t, r, t) = v_(z_t, t) - (t-r) \frac{d}{dt} u_\theta(z_t, r, t)$,这恰好就是我们的MeanFlow恒等式,而上面说了,这个等式是u为边缘平均速度的充要条件,因此在优化充分的情况下,模型的输出就是真实的边缘平均速度,那么模型输出的数值导数就是u关于t的导数了。当然,这两点都是在理想情况下讨论的,在实际训练中,样本不可能无限多,优化不可能完全充分,因此这两种近似还是有误差,但从理论上来说,这两种近似是有一定合理性的。并且,如何减少这种误差的影响,也是MF的一个重要研究方向。
iMF
iMF,即improved Mean Flow,顾名思义是对Mean Flow的一系列改进,下面逐条介绍原MF的问题以及iMF的改进:
边缘瞬时速度的稳定化
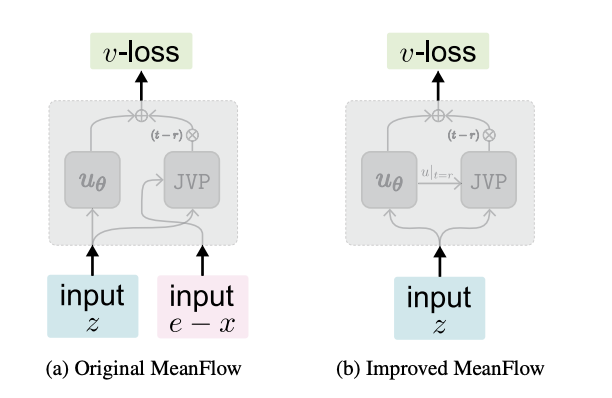
原始MF中,条件瞬时速度$v_{cond} = e - x$是一个高方差的随机变量。将其作为 JVP 的输入切向量,会导致整个损失函数(u-loss)具有极高的方差和不稳定性,优化过程难以收敛。
iMF 不再使用高方差的条件速度$v_{cond}$作为 JVP 的切向量输入,而是使用网络预测的边际速度$v_\theta(z_t, t)$。真实瞬时速度$v(z_t)$是一个平滑的场,表示从噪声往数据走的方向,网络预测的$v_\theta$则是对这个平滑场的近似,连续、平滑、方差小,且随着训练逐步变准,于是 JVP 的输出变得更平稳,训练变得稳定。
至于如何获得这个$v_\theta$,iMF 提出两种方案:一是在原始模型$u_\theta(z_t, r, t)$上直接令r=t,这样就得到了一个边缘瞬时速度的预测$v_\theta(z_t, t) = u_\theta(z_t, t, t)$;二是在$u_\theta$网络中增加一个轻量级的辅助头来专门预测$v_\theta$,并施加 Flow Matching 损失进行训练。虽然训练时增加了参数,但推理时仅需$u_\theta(z_t, r, t)$,无额外开销。实验结果表明,这两种方案均能显著提升性能,尤其是在模型容量较大时,第一种方案能更好地利用模型的能力。
这里我第一次看的时候有点疑惑,因此详细讲讲:
首先,在原始MF中,模型输出$u_\theta$的拟合目标是$u_{target} = v_{cond}(z_t, t) - (t-r) \frac{d}{dt} u_\theta(z_t, r, t)$,其中$v_{cond} = \epsilon - x$。也就是说,优化的目标是让模型输出尽可能接近$u_{target} = v_{cond}(z_t, t) - (t-r) \frac{d}{dt} u_\theta(z_t, r, t)$,即
那么loss就是在u上计算的,即u-loss。通过简单的移项,我们可以得到等价的优化目标:
定义:
于是就变成:
这样就得到了计算在v上的loss,即v-loss。也就是说,原始MF的优化目标在u上计算的loss和在v上计算的loss是等价的。
这样很好,无论是计算v还是计算u都能够优化我们的模型,然而问题在于其中的$\frac{d u_\theta}{dt}$项。
这是$u_\theta$对时间t的全导数,根据链式法则,有$\frac{d}{dt} u_\theta(z_t, r, t) = v(z_t, t) \partial_z u_\theta + \partial_t u_\theta$,如果用$v_{cond}$来近似$v(z_t, t)$的话,就是:
计算$v_{cond} \partial_z u_\theta$这一项需要计算网络输出$u_\theta$对输入状态$z_t$的雅可比矩阵$\partial_z u_\theta$,然后与向量$v_{cond}$做乘积,这就是所谓的雅可-向量积(JVP)。由于$v_{cond}$是一个高方差的随机变量,噪声会被 Jacobian 放大。iMF 论文也明确指出,conditional velocity 的方差会被 JVP 显著放大,导致原 MF loss 高方差、不稳定。
因此,iMF不再让条件速度$v_{cond} = \epsilon - x$作为JVP的输入切向量,而是使用网络预测的边缘瞬时速度$v_\theta(z_t, t)$。
于是 iMF 的预测是:
然后仍然做:
也就是说,iMF与MF的u-loss不同,它是用的是v-loss。
总结一下,在训练时,我们会有两个地方用到$v_{cond}$:
- 作为loss计算的target,即$\left|
V_\theta^{\text{iMF}}-(\epsilon-x)
\right|^2$中的$\epsilon-x$项。target 有噪声(方差大)是可以接受的,只要噪声的期望为0,MSE 最优解仍然是条件期望。所以这里依然保留$\epsilon-x$作为target。 - prediction function 的输入,即$\partial_z u_\theta \cdot (\epsilon-x)$,作为JVP的输入切向量。iMF 认为真正麻烦的是这个位置,因此通过用网络预测替换这个高方差的随机变量,来稳定训练。
所以,iMF减小的不是 target 方差,而是 prediction function / JVP 内部的方差,用网络输出替换的也不是loss里的label,而是JVP内部的输入切向量。
CFG的灵活化
MF的CFG训练是直接将CFG的参数$\omega$融入平均速度u里,也就是说在训练和推理时使用的$\omega$都是固定的,不能自由调节。既然 MF 会因为 $\omega$ 固定而导致速度场僵硬,那干脆把 $\omega$ 当成网络输入,让模型学习「不同 $\omega$ 对速度场的影响」。
于是 iMF 把网络定义扩展为:
其中 $\Omega$ 是 CFG 相关参数集合,包括 $\omega$。
灵活性的实现:
- 训练阶段: 在训练时,$\omega$ 从预设范围 $[1.0, \omega_{max}]$ 内随机采样,使模型学会适应不同引导强度。
- 推理阶段: 用户可以根据需求,在推理时灵活选择最佳的 $\omega$ 值。研究发现,训练更久或使用更多 NFE 的模型倾向于更小的最优 $\omega$ 值,iMF 的灵活设计解锁了这一性能潜力。
进一步扩展:
引导不仅有强度 $\omega$,还有一个时间区间 $[t_{min}, t_{max}]$:
- 在早期加大引导提升合理性
- 在中后期降低引导提高多样性
iMF 进一步将 CFG 区间 $[t_{min}, t_{max}]$ 也作为条件引入 $\Omega$ 中。于是 iMF 有机会学会在不同时间段,应该给予不同强度的引导。
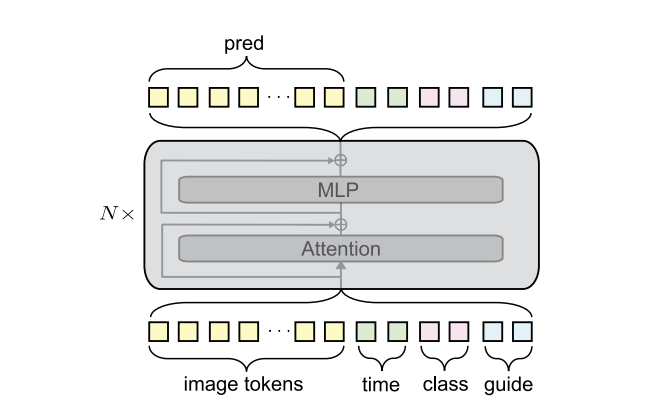
更高效的上下文条件输入架构
iMF 要处理更多异构条件输入:
- 两个时间步:$t$、$r$(MF 特有的双时间结构)
- 类别 / 文本 token:$\mathbf{c}$
- 引导条件:$Omega = {\omega, t_{min}, t_{max}}$
这些条件之间形态完全不同:有的是标量,有的是区间,有的是 embedding,还有图像潜空间 token(比如 16x16 的 latents)。
如何在一个 Transformer 中整合这些异构信息?传统方法是:使用 adaLN-zero(DiT相关工作)。但adaLN-zero 需要为 Transformer 的每一层产生一份参数,所以参数量爆炸性增长。
而 iMF 采用了改进的上下文条件化 (In-context Conditioning) 策略:
- 多 Token 输入: 将每个条件 (如 $t, r, \mathbf{c}, \omega$)转化为多个可学习的 Token (例如,类别 8 个 Token,其他条件 4 个 Token)。把所有条件当成提示词一样,直接喂给 transformer。
- 序列拼接: 所有条件 Token 与图像潜空间 Token 沿序列轴拼接,共同输入给 Transformer 块。
- 移除 adaLN-zero: 这种设计允许 iMF 完全移除参数量巨大的
adaLN-zero模块,同时保持甚至超越其性能。因为条件已经进入 transformer 自身的序列中,所有层都能通过 self-attention 看到这些条件。
架构收益: 移除 adaLN-zero 带来了显著的工程优势:模型参数量减少了约 1/3 (例如,iMF-Base 模型从 133M 降至 89M),极大地提升了模型设计的灵活性和部署效率。
潜在的局限挑战:
- 对 VAE 的依赖: iMF 仍然在 VAE 的潜空间中进行操作,完整的图像生成过程需要 VAE 的编解码。消除或优化对 VAE Tokenizer 的依赖,实现更高效的端到端像素空间 1-NFE 生成,是未来快进模型的重要方向。
- 高阶梯度: iMF 通过使用
stop-gradient($\mathrm{JVP}_{sg}$) 来避免高阶梯度带来的优化困难。深入研究并解决 MeanFlow 目标函数中的高阶梯度问题,可能进一步提升训练效率和性能。 - 最优参数搜索: iMF 的最终性能依赖于推理时最优 CFG 参数($\omega$ 和区间)的搜索,这在实际部署中仍需额外的调优工作。
(本文后半部分主要参考了知乎作者tomsheep的文章)