FD-loss:一种新的优化目标
原论文:Representation Fréchet Loss for Visual Generation
预备:Fréchet Distance
Fréchet Distance(FD)是一种衡量两个概率分布之间差异的指标,常用于评估生成模型生成图像的质量。它通过计算生成图像和真实图像在特征空间中的均值和协方差来衡量两者之间的距离。
令 $\phi(\cdot)$ 表示一个特征提取器。给定真实图像 $\mathcal{R}={\mathbf{x}_i}$ 和生成图像 $\mathcal{G}={\hat{\mathbf{x}}_i}$,它们的特征分布被建模为具有均值和协方差的多元高斯:
两个高斯分布之间的 FD 为:
当 $\phi$ 是 Inception-v3 时,这就成为 Fréchet Inception Distance(FID)。
在标准评估中,$(\boldsymbol{\mu}_r, \boldsymbol{\Sigma}_r)$ 从训练集预先计算一次,而 $(\boldsymbol{\mu}_g, \boldsymbol{\Sigma}_g)$ 从大的生成样本总体中估计,通常为数万量级。
通过FD的计算,我们可以得到几个结论:
- FD是一个数据分布指标(distributional quantity),而不是数据本身的指标,无法从单个样本出发计算FD。FD的计算依赖于大数定律,只有提供足够多的样本(上万级别)时,FD才能较为准确的衡量整个分布的性质。
- FD本质上是通过特征提取器$\phi$(一般是一个神经网络)将图像映射到一个特征空间,在该空间中计算模型生成数据与真实验证数据的差异程度。这个特征空间以及特征映射的过程,与对应的表征模型$\phi$是强相关的,如果表征模型不能很好的贴合我们的某种要求,那么在这一标准下得到的“最佳”模型也很有可能实际上是质量很差的。
引入
长期以来,诸如 Fréchet Distance 的分布距离只作为生成器生成图像质量的评估指标,而不是直接优化的目标函数。我们使用样本级的指标,如MSE/perceptual loss,来训练生成器,训练完毕后,再使用分布级的指标,如FD,来评估生成器的性能。这种训练-评估分离的方式存在一个问题:我们优化的目标函数与我们最终评估生成器性能的指标之间存在不一致性。这种不一致性可能导致我们训练出的生成器在评估指标上表现不佳,即使它在训练过程中表现良好。换句话说,如果我们有一个能够很好表达图像分布的“真实程度”的特征空间,那么我们能不能直接在这个特征空间中优化生成器呢?
问题
从原理上讲,FD是完全适用于模型的训练损失的:FD没有离散性操作,是完全可微的(原文“This separation has been a matter of practicality rather than principle: FD has always been differentiable, yet reliable estimation requires populations far beyond a training batch.”)。
将FD用于训练的问题在于,如果想要较为准确的评估生成器的FD,我们需要大量的样本(上万级别),而在训练过程中,由于硬件和时间的限制,我们通常只能使用较小的批次(几十到几百);而如果我们使用与batch大小相同的样本数量来计算FD,那么由于样本过少,我们得到的FD值将会非常不稳定(方差非常大),无法有效地衡量生成器的生成效果,从而误导生成器的训练(“Our experiments confirm that optimizing batch-wise FD degrades base generators”)。
既然计算FD需要大样本量,而参与训练(BP)又需要小样本量,那么Representation Fréchet Loss for Visual Generation这篇文章提出的想法其实很自然:将用于 FD 估计的 总体规模(例如 50k)与用于梯度计算的 批大小(例如 1024)解耦,从而得到一个新的训练优化目标:FD-loss。
FD-loss的实现
FD-loss的解耦思想很简单:在大的样本窗口上计算FD,但只在当前batch的样本上计算梯度并反向传播。具体来说,文章给出了两种实现:基于队列的评估器和基于EMA的评估器。
基于队列的评估器
基于队列的实现维护了一个固定大小的样本队列,该队列长度为N,其中N>>batch_size。每次训练迭代时,生成器每生成一个batch的样本数据,就先用表征模型$\phi$提取这些样本的特征,并将这些特征加入到队列中,同时移除队列中最旧的batch个样本的特征。这样,队列中始终保持着最近N个样本的特征表示。FD 使用完整队列中全部样本的均值和协方差计算。在反向传播期间,只有当前批次特征携带梯度;来自先前迭代的队列中特征被视为常数。
基于EMA的评估器
基于EMA的评估器可以完全避免存储特征队列。这里我们维护特征一阶矩和二阶矩的指数移动平均(EMA)。令 $\beta \in (0, 1)$ 表示 EMA 衰减率,并令 $\boldsymbol{\mu}^{(t)}_{\mathrm{g}}$ 和 $\mathbf{M}^{(t)}_{\mathrm{g}}$ 表示迭代 $t$ 时一阶矩和二阶矩的运行估计。给定当前批次中生成图像的特征 ${\phi(\hat{\mathbf{x}}_i)}_{i=1}^{B}$,我们将批次矩定义为:
并将运行估计更新为:
从下式得到协方差:
然后使用 $(\boldsymbol{\mu}^{(t)}_{g},\, \boldsymbol{\Sigma}^{(t)}_{g})$ 计算 FD,梯度只通过当前批次反向传播。
EMA实现相比队列实现的优点在于,它不用维护一个巨大的特征队列,因此在多个表征模型或大规模模型上更具可扩展性。
关于“仅在当前batch上计算梯度”,主要是通过detach()实现,代码为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# G: 生成器
# phi: 冻结的表征模型
# (mu_r, sig_r): 真实特征统计量
# (mu_ema, M_ema): EMA 均值和二阶矩
# beta: EMA 衰减
# z: 当前批次噪声
x = G(z)
feat = phi(x)
feat = all_gather(feat) # 跨设备收集
# 队列版本:
# gen_feats = cat([queue.detach(), feat])
# mu_g, sig_g = compute_stats(gen_feats)
# EMA 版本:
mu_b, M_b = batch_moments(feat)
mu_g = beta * mu_ema.detach() + (1 - beta) * mu_b
M_g = beta * M_ema.detach() + (1 - beta) * M_b
sig_g = M_g - mu_g @ mu_g.T
loss = FD((mu_g, sig_g), (mu_r, sig_r))
loss.backward()
optimizer.step()
# 队列版本:
# queue.enqueue_and_dequeue(feat.detach())
# EMA 版本
mu_ema = mu_g.detach()
M_ema = M_g.detach()
个人的几点理解:关于FD-loss的两重近似及其合理性
个人认为,FD-loss实际上对FD做了两种近似:生成器FD的近似和FD梯度的近似。
FD梯度的近似
理想情况下,我们要么使用全量样本计算FD,然后在全量样本上BP;要么仅在batch上计算FD,然后在batch上BP。也就是说,loss(FD)的计算和反向传播的作用范围是一致的,这样可以确保参数始终往FD的最速下降方向更新(取决于优化器的实际处理)。但这里使用了“全量loss(FD)+局部BP(batch)”的方式,这就导致了我们实际上是在用全部N个样本中的Batch_size个样本的梯度方向来近似全部样本的梯度方向。这就类似于从全部N个梯度中采样了batch_size个梯度来近似全部N个梯度的期望(这里的FD是多元素耦合的,因此不是严格意义上的采样操作,此外该“采样”也不是无偏的,但可以通过学习率调整来抵消这一点)。这样做的合理性,个人认为有两个保证:一是我们相信真实数据是服从某种低维规律的(流形假设),因此这batch_size个梯度与能够最小化FD的“全量梯度”大体上方向一致,其方差不至于大到破坏我们的优化过程;二是我们通过多轮迭代,采集了很多批batch_size的样本,这相当于增加了采样的个数,提高了近似的精度。
生成器FD的近似
文中强调,队列实现和EMA实现都是on-policy的,实际上这里也应该是“近似on-policy”。理论上讲,我们想要得到当前参数状态下生成器的FD,应该全部使用当前参数状态下生成的样本(对于队列实现来说,需要完整生成N个样本)来计算FD;但实际上,我们是使用“最近的N/batch_size个参数状态所产生的N个样本”/“最近的参数状态的EMA指标”来计算FD的,也就是说,计算出来的FD只是当前生成器的真实FD的一个近似,但是,由于选取的是最近的N个样本(queue),EMA对近期指标的偏好(EMA),这个近似是较为准确的。此外,由于queue是不具备EMA的“近期偏好”特性的,因此使用queue实现的版本表现就比使用EMA的差一点,这也是合理的。
在实践中,会先用N个样本填满queue或EMA,以进行warm start。
多表征 FD-loss
有了可训练优化的FD-loss,我们就可以考虑将不同表征模型的FD-loss进行加权组合,得到一个多表征 FD-loss。这样做的好处在于,不同的表征模型可能会捕捉到图像分布的不同方面,因此通过组合多个表征模型的FD-loss,我们可以得到一个更全面、更鲁棒的优化目标,从而提升生成器的性能。
由于不同FD-loss的数值尺度不同,因此相加之前先进行normalization操作:
分母上的stop-gradient表示将FD-loss除以大小为其自身的常数,因此该loss项在数值上大约为1.
一种新的评估指标
作者发现,FID相当低的生成器可能实际上具有相当糟糕的生成效果,因此FID并不能完全反映生成器的质量。为了解决这个问题,作者提出FD ratio,用同一特征空间中真实验证图像的 FD 对生成图像的 FD 进行归一化。令 $\mathcal{T}$ 表示 ImageNet 训练集,$\mathcal{V}$ 表示验证集,$\mathcal{G}$ 表示一组生成图像。对于表征模型 $\phi_i$,我们定义归一化 FD 比率,缩写为 $\mathrm{FDr}$:
这一比率是无单位的,并且可解释为生成图像与验证图像的感知距离的比例。FDr的值越接近1,说明生成图像与验证图像在特征空间中的分布越接近验证图像的分布,从而表明生成器的性能越好。
这引出了$\mathrm{FDr}^{K}$。 通过在 $K$ 个表征模型上平均这些归一化比率来定义 $\mathrm{FDr}^{k}$:
这是一个单一的多表征指标,同时保留了逐模型比率的解释。即使在 Inception 特征空间中超过验证图像,但一旦跨多样表征评估,仍然可能显著劣于验证图像。
作者使用 6 个代表性模型实例化 $\mathrm{FDr}^{k}$,它们跨越有监督、自监督和视觉-语言目标,并覆盖 CNN 与 ViT 架构:Inception-v3 、ConvNeXt-v2 、DINOv2 、MAE 、SigLIP2 和 CLIP 。$\mathrm{FDr}^{6}$提供了比单一表征更全面的自动评估指标,能够更好地反映生成图像的质量。
实验及其效果
简单列举一下实验结论:
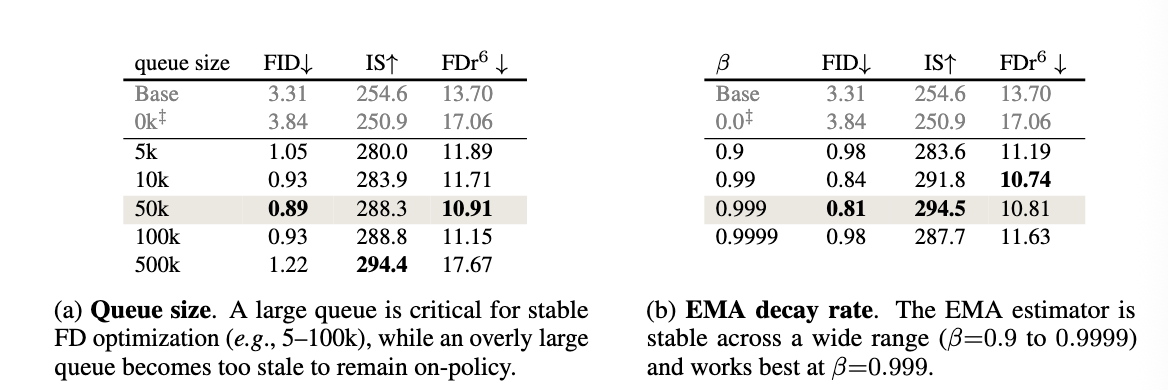
- queue过大/beta过大会导致信息过于陈旧,接近off-policy,导致性能下降;过小则会导致信息过于嘈杂,导致性能下降。适中的queue size/beta比较理想。
- 用FD-loss后训练一步生成器,在FID和$\mathrm{FDr}^{6}$上都能得到显著提升。
- FD-loss也可以将多步生成器后训练为有效的单步生成器。具体而言,给定高斯噪声 $z$,我们只在终止时间步运行模型一次,并将其输出解释为干净图像的一步预测。例如,对于 velocity-prediction 模型,$\hat{x}_0 = z - v_\theta(z,\; t{=}1)$;对于 $x_0$-prediction 模型,$\hat{x}_0 = x_\theta(z,\; t{=}1)$,假设 $z_{t=1}$ 是纯高斯噪声。
- FID很低的模型,在$\mathrm{FDr}^{6}$上可能表现很差,视觉上也失真严重,说明FID并不能完全反映生成器的质量。使用多个表征模型后训练出的模型可以得到较低的FID和较低的$\mathrm{FDr}^{6}$,并且在视觉上质量也很好。其中FD-SIM效果最好,即FD-SigLIP+Incep.+MAE。基于 CNN 的表征倾向于改进 FID,而基于 ViT 的表征更大幅度地改进更广泛的 $\mathrm{FDr}^{6}$。
- FD-loss扩展性良好:它可以与单步生成/多步生成,latent space/pixel space,有条件/无条件输入模型相结合。
总结
FD-loss解决了分布指标难以用于模型训练的问题。它证明:一旦总体规模和梯度规模被解耦,分布距离就可以直接作为训练损失。这一工作具有很强的泛用价值,并不局限于图像生成,它将分布级目标引入了模型的训练过程,引导人们转向关注更好的表征空间的选择和表征的多样性真实性。目前,FD-loss仅仅作为后训练的目标,对于如何在从头训练模型的过程中引入分布级指标,还有待探索和实现。