近期论文的takeaway
L2P: UNLOCKING LATENT POTENTIAL FOR PIXEL GENERATION
- 传统LDM的瓶颈很大程度上在于VAE encoder和VAE decoder,VAE参数量大,推理速度慢,且decoder无法重建出细节较好的图像。直接训练一个pixel space的模型可以解决这些问题,但是pixel space对GPU和数据的要求很高。能不能利用LDM模型的diffusion组件中的先验知识,训练一个pixel space的模型呢?L2P就是这么做的。
- L2P直接使用LDM的DiT,从而能够有效使用DiT权重中的大量先验知识。它去掉了VAE encoder和decoder,通过增加patch的大小,使得latent space中的DiT能直接用于pixel space。使用一个轻量的U-net decoder接在DiT最后作为像素生成器。训练时直接在像素空间计算v-loss,冻结 DiT backbone 的中间层,并只训练浅层输⼊和输出层(初始输⼊投影层、DiT 的前n个和后n个 blocks,以及新添加的 Detailer Head)来学习latent-to-pixel 模态转换。训练时无需重新收集数据集,只要把原LDM的输出作为L2P的label即可。此外,这种方法天然适配高分辨率生成,通过进一步增大patch size,L2P可以直接生成4K图像。
- 与VAE decoder相比,L2P在推理时间和显存占用上都有显著优势。
PiD: Fast and High-Resolution Latent Decoding with Pixel Diffusion
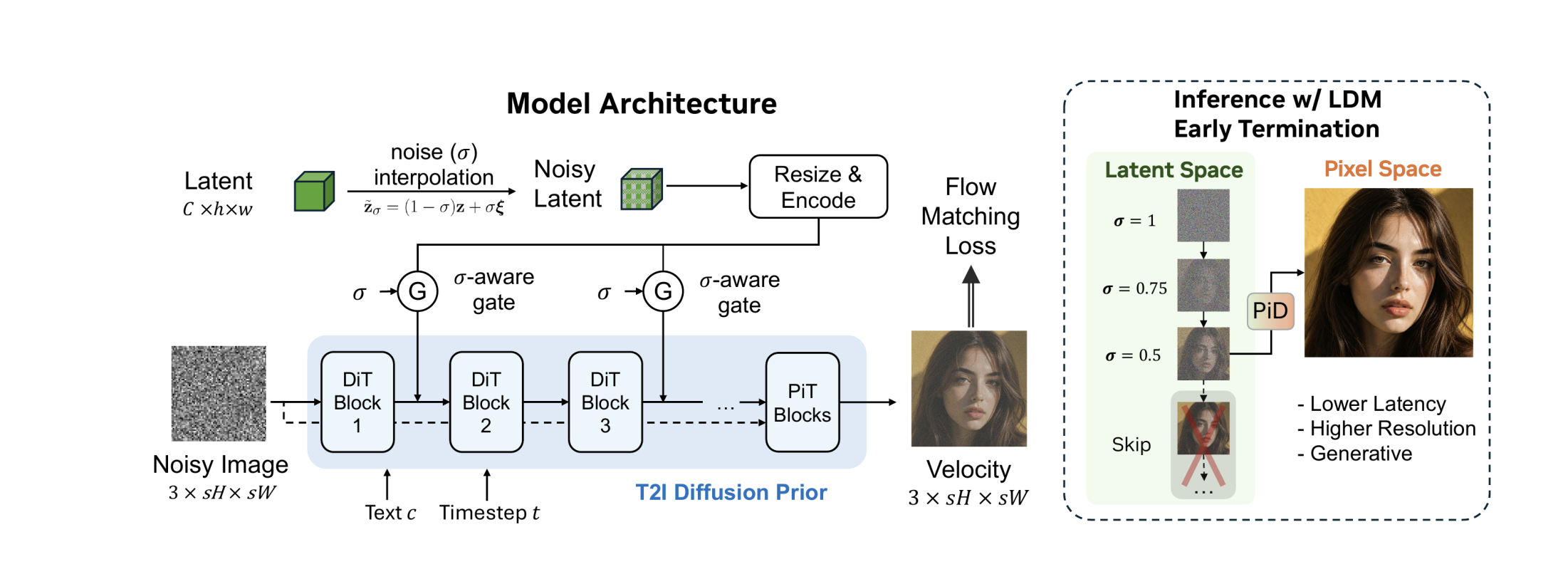
- 传统高分辨率图像生成方法通常采用两阶段pipeline,即先通过VAE decoder从diffusion模型输出的latent space生成一个低分辨率图像,然后再通过一个超分模型将其放大到目标分辨率。而VAE decoder的目标是重建encoder的输入图像而不是合成更多细节,因此它会丢失一些细节信息,导致生成的图像质量不佳。此外,VAE还具有推理速度慢,显存占用大等问题。PiD通过一个latent-conditioned pixel diffusion decoder直接建立latent representation到high-resolution pixel space的映射,将latent decoding过程建模为conditional pixel-space generation,在单个扩散解码阶段中统一解码和高分辨率上采样,避免了VAE decoder的问题,实现更小的显存占用和更快的生成。此外,这个decoder可以在带噪声的latent下生成,而不要求输入一个干净的latent,这样就可以减少latent diffusion的步数,从而加速推理。
- 如图,上面的绿色方块表示latent diffusion输出的latent representation,这个latent是可以带噪声的,也就是允许latent diffusion的早停,在训练时也会刻意向latent中插值进噪声。然后该latent被resize至pixel space diffusion的patch大小,再经过一个简单的编码器变为token,线性投影到pixel diffusion decoder的隐藏维度,最后通过一个门控融入到pixel diffusion decoder的每个block中作为条件输入,一般是通过concat到每个token的通道维或直接相加(文章中是直接相加),这个门控简单来讲就是实现latent的噪声水平越大,其“可信度”就越低,condition注入强度越弱。下面是一个训练好的T2I pixel-diffusion model作为decoder,可以是PixelDiT等模型,然后通过这种latent-conditioned来微调,仍然使用v-loss。下面这个pixel diffusion还可以通过dmd2蒸馏以进一步加速生成。
- 简单来讲,PiD就是把VAE decoder换成了一个pixel-space diffusion decoder,原来的latent-diffusion的输出作为pixel-diffusion的condition,用以提供全局结构信息和语义约束,而pixel-diffusion则通过其先验知识更好的生成细节和纹理,从而提升生成图像的质量。
PixNerd: Pixel Neural Field Diffusion
- 解决在pixel-space diffusion在大patch size下,将DiT最后一层的token隐藏表示映射到该patch的pixel RGB空间的linear层难以很好的捕捉细粒度细节的问题。传统的DiT解码头直接将一个d维的token映射到(patch_size, patch_size, 3)的RGB空间,这在patch size较大时会导致细节丢失,并且像素间的相对位置关系也无法被很好地建模。PixNerd用 patch-wise neural field 替代这个线性 patch decoder。
- 具体来讲,每个patch都对应一个小MLP,向这个小MLP输入patch中对应像素的坐标,就会给出这个patch中该坐标对应的预测velocity。PixNerd先用DiT最后输出的patch token,通过一个线性层来预测每个patch对应的小MLP的权重,然后对patch内每个像素的坐标进行位置编码(DCT-basis编码),该编码与该像素的noisy pixel值(即原始RGB值)做concat后输入该patch的MLP,MLP输出该像素的velocity。通过这种方式,PixNerd能够更好地捕捉细节信息,并且能够建模像素间的相对位置关系,从而提升生成图像的质量。
- 不是重新发明 diffusion objective,而是改了 patch 内像素级解码方式。这个改动非常针对大 patch 的问题:让每个像素都能基于自己的局部坐标获得不同预测,而不是让一个线性层一次性吐出整个 patch。PixNerd 的 takeaway 是:在像素空间做 DiT 不一定要走小 patch 高 token 或 cascade 多阶段路线;可以用大 patch 控制 token 数,再用 neural field + DCT 坐标编码补回 patch 内细节。它是 pixel-space diffusion 的一个很有潜力的结构性改进,但目前还不是 latent diffusion 的终结者。
DiP: Taming Diffusion Models in Pixel Space
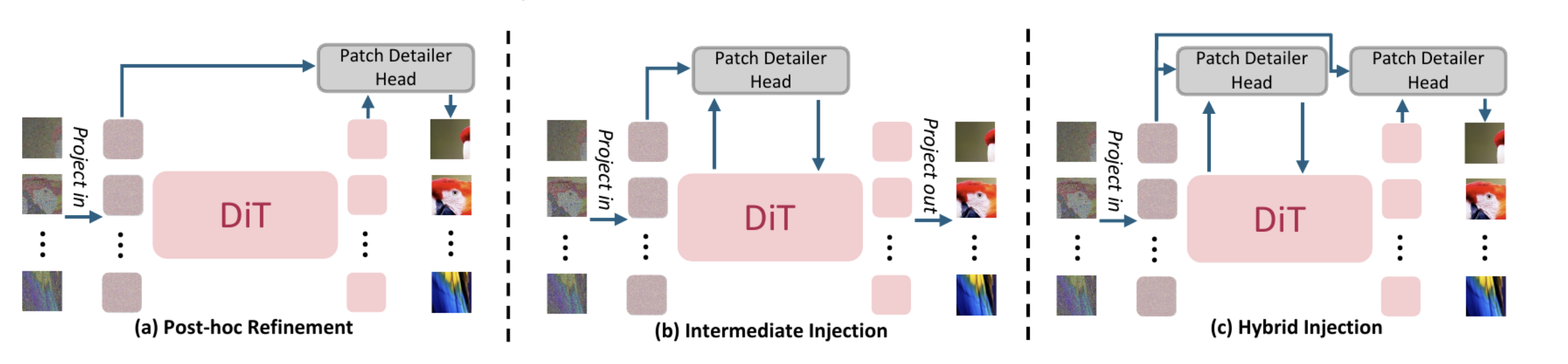
- 这一篇的动机和上一篇很相似:LDM快,但由于VAE decoder,质量不好,pixel-space理论上质量好,但token序列太长,效率低下,如果使用更大的patch,又会影响质量,因此怎么建立big patch下token到pixel的映射是一个关键点。DiP的核心思想在于global与local的解耦:DiT的attention机制擅长建模 patch 之间的宏观关系,但它会将每个 patch 内丰富的 spatial information 压缩为单个 flattened token,模型能够熟练学习 patch 的 coarse-level layout 和 arrangement,但难以建模每个 patch 内的 fine-grained textures 和 high-frequency details,从⽽限制其图像⽣成性能上限。为了解决这个问题,作者用一个专门模块增强 global Transformer,该模块显式重新注⼊ local details 缺失的 inductive bias。这样,模型既保留了big patch DiT的高计算效率与global context awareness,又能通过 Patch Detailer Head所具备的 locality 来补回 big patch 带来的细节损失,从而提升生成图像的质量。
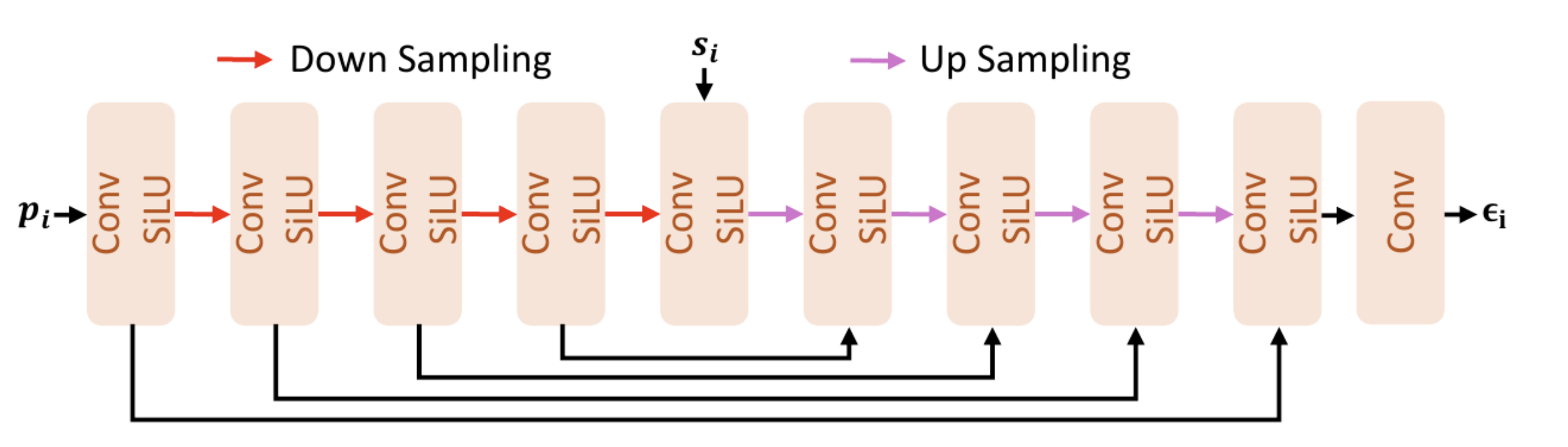
- 具体来讲,DiP保留原来的DiT backbone架构,但使用大的patch size,在DiT最后,将原来的简单linear层换成Patch Detailer Head,接受DiT输出的每个patch token和原始noisy pixel patch作为输入,输出该patch的velocity。 Patch Detailer Head 在每个 patch 上独⽴且并⾏运⾏。经过实验,作者发现Patch Detailer Head接受最后的DiT block的输出token(而不是中间层的token)效果最好,使用一个轻量的u-net比使用其它结构更好,这形成了清晰的职责分离:DiT 仅负责 global modeling,Patch Detailer Head 仅负责 local refinement。 此外,使用Post-hoc Refinement(即Patch Detailer Head 仅放置在最终 DiT block 之后)使得这一组件是即插即用的,可以直接在预训练的 DiT 上微调得到 DiP,而不需要从头训练。
- 与简单的堆深度,宽度相比,Patch Detailer Head 只增加很少参数,却显著改善质量。DiP实现了很好的速度—质量 trade-off:更轻,更快,更好。它证明像素空间扩散模型不一定非要靠小 patch 暴力建模细节;可以用大 patch 的 DiT 负责全局结构,再用一个轻量局部 head 补回 patch 内高频细节,从而同时获得 pixel-space 的保真度和接近 latent diffusion 的效率,关键不是“堆大模型”,而是分工和“补归纳偏置”。
- 这篇文章让我想到JiT:JiT的做法很简单粗暴,就是pixel space+大patch+linear decoder,那为什么JiT的效果还不错,并没有出现本文说的问题呢?个人认为,这主要是因为JiT使用x-pred而不是v-pred,结合流形假设,预测x相对更可行,此外,JiT的训练是相当充足的,也就是可能通过scaling掩盖了一些潜在的问题。这启示我们,或许应该更多在x-pred上做文章?
PixelDiT: Pixel Diffusion Transformers for Image Generation
- VAE decoder会损失细节,且VAE decoder本身不能完全还原VAE encoder的输入图像,是有损重建,因此latent的扩散模型将不得不继承并学习这种有损的重建过程,导致生成图像的质量受限。LDM的这种两阶段流水线会产生误差累积,因此我们希望有一个单阶段,端到端(pixel space)的模型。
- PixelDiT是一个单阶段,完全基于Transformer(没有U-net等),pixel space,无VAE的端到端模型。它通过一个双层级DiT结构,将全局语义学习与像素级纹理细节解耦,从而实现⾼效像素建模。具体来说,它先将带噪声图在大patch下输入一个patch-level DiT,学习全局结构和语义关系,然后将该DiT的输出token进行pixel-wise AdaLN调制后作为condition输入到一个像素级(1·1 patch)的pixel-level DiT中,后者专注于建模像素级的纹理细节和高频信息,该pixel-level DiT的输入依然是原始带噪声图的像素。这种组织允许大多数语义推理发生在低分辨率⽹格上,从⽽降低 pixel-level pathway 的负担并加速学习。这也给我们一个启发:不要把Transformer看作生成器,它更贴切的定义应该是翻译器/解释器/理解器,“生成”仅仅是建立在它的理解能力之上的一个附加技能。还有,从架构上看,负责生成的最终模块实际上仅仅是pixel-level DiT,而patch-level DiT只是为它提供恰当的condition,这说明为DiT设计合适的condition很重要,不要指望一个单一的backbone能包揽从理解到生成的全流程,解耦和分工往往很有效。
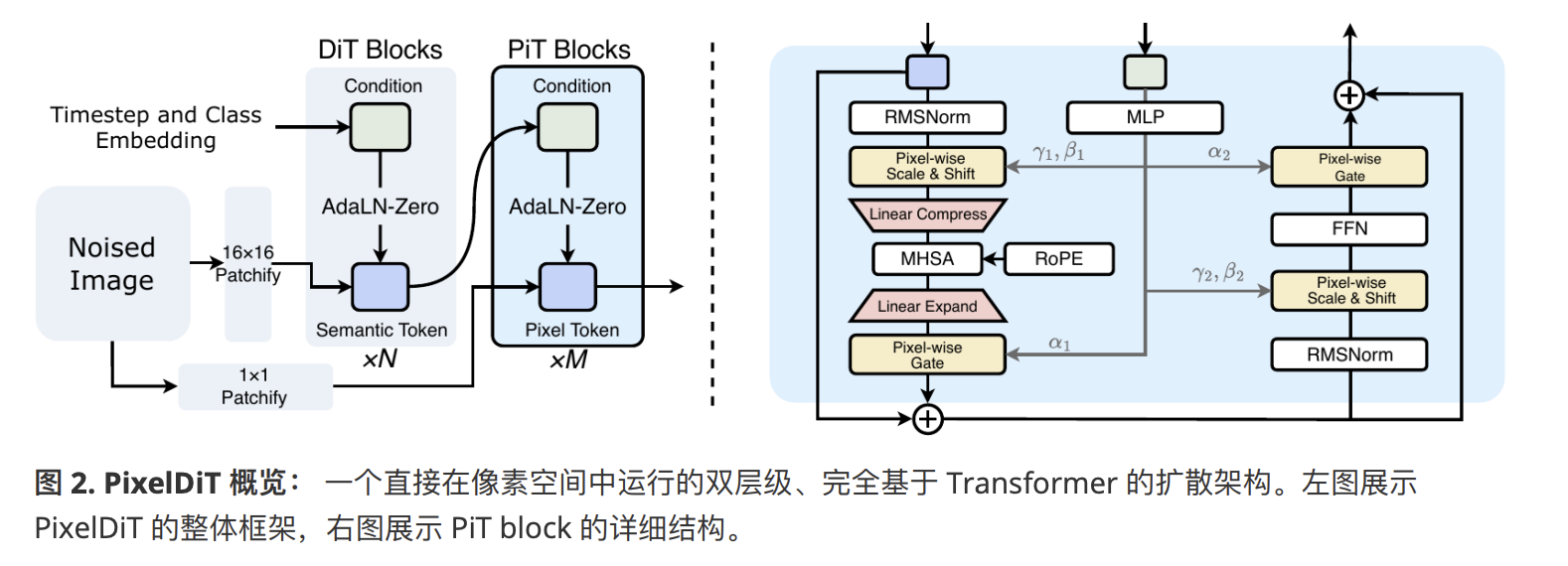
- PixelDiT的主要创新有两点:一个逐像素的DiT condition调制机制(pixel-wise AdaLN)用于信息融合,以及一个token向量压缩处理手法(pixel token compaction)用于缓解计算上的压力。
- 在 pixel-level pathway 中,每张图像通过线性层被嵌⼊为每个像素⼀个 token,为了与 patch-level 语义 token 对⻬,我们将其 reshape 为 batch_size·length 个由 patch_size^2 个像素 token 组成的序列。对于每个 patch,我们已经有了一个语义条件 token来总结全局上下⽂。一个直接的 patch-wise 调制会为⼀个 patch 内的所有p^2个像素重复相同参数,这⽆法捕捉稠密的逐像素变化。作者通过线性投影 将 $s_{\mathrm{cond}}$ 扩展为 $p^2$ 组 AdaLN 参数,从而为每个像素分配独立调制:
并将 $\Theta$ 的最后一维划分为六组,每组大小为 $D_{\mathrm{pix}}$,得到 $(\beta_1, \gamma_1, \alpha_1, \beta_2, \gamma_2, \alpha_2) \in (\mathbb{R}^{(B \cdot L) \times p^2 \times D_{\mathrm{pix}}})^6$。这些调制参数是学习得到的,并且在每个像素处不同。它们通过 pixel-wise AdaLN 应用于 $X$,实现像素特异性更新;相比之下,patch-wise AdaLN 将单组参数广播到 patch 内所有像素,因此无法捕捉这种空间变化。![]()
5.Pixel Token Compaction技术:在pixel-level DiT中,直接对每个像素的token做注意力计算会导致计算量过大,因此在做全局注意力之前临时将每个patch内的p^2个像素 token 压缩为⼀个紧凑 patch token,之后再将经注意⼒处理的表示扩展回原始像素token数量和维度。这将注意力序列长度从 $H \times W$ 降低到 $L = (\frac{H}{p})(\frac{W}{p})$,即减少 $p^2$ 倍;当 $p = 16$ 时,这带来 $256\times$ 的缩减,同时通过 pixel-wise AdaLN 和学习到的扩展保留逐像素更新。通过可学习的的线性映射实现compaction算子:一个线性映射 $\mathcal{C} : \mathbb{R}^{p^2 \times D_{\mathrm{pix}}} \rightarrow \mathbb{R}^D$ 联合混合空间和通道维度,并配对一个扩展(还原) $\mathcal{E} : \mathbb{R}^D \rightarrow \mathbb{R}^{p^2 \times D_{\mathrm{pix}}}$。这一 compress-attend-expand 流水线保持全局注意力高效。不同于 VAE 中的有损瓶颈,这一机制仅为注意力操作瞬时压缩表示。关键的是,这种 compaction 纯粹用于降低自注意力的计算开销;它不会损害细粒度细节,因为高频信息通过残差连接和学习到的扩展层被保留,这些连接和层有效绕过了像素-token 瓶颈。
6.单阶段像素空间扩散相⽐两阶段潜空间⽅法,为视觉合成提供了⼀种更简单、更优雅且领域⽆关的范式。然⽽,现有像素空间⽅法与潜扩散模型相⽐仍显示出显著质量差距。这⼀差距很可能源于两个主要挑战:1、像素空间数据和噪声分布相⽐潜空间对应物本质上更复杂;2、缺少成熟训练 recipe,包括有效架构、⽬标、噪声调度和优化设计。该工作表明通过合适的架构设计,尤其是针对像素 token 建模的设计,像素空间扩散 Transformer 可以在类别条件和⽂本条件⽣成任务上达到与潜扩散相当的图像质量,有效且高效的像素建模是实用像素空间扩散的关键。
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
- 基本结构和上面几篇类似:通过两个部分的模型解耦全局和局部细节,全局用patchify+DiT,输出token作为condition输入一个pixel decoder头,该decoder输入原始$x_t$像素值,输出velocity。
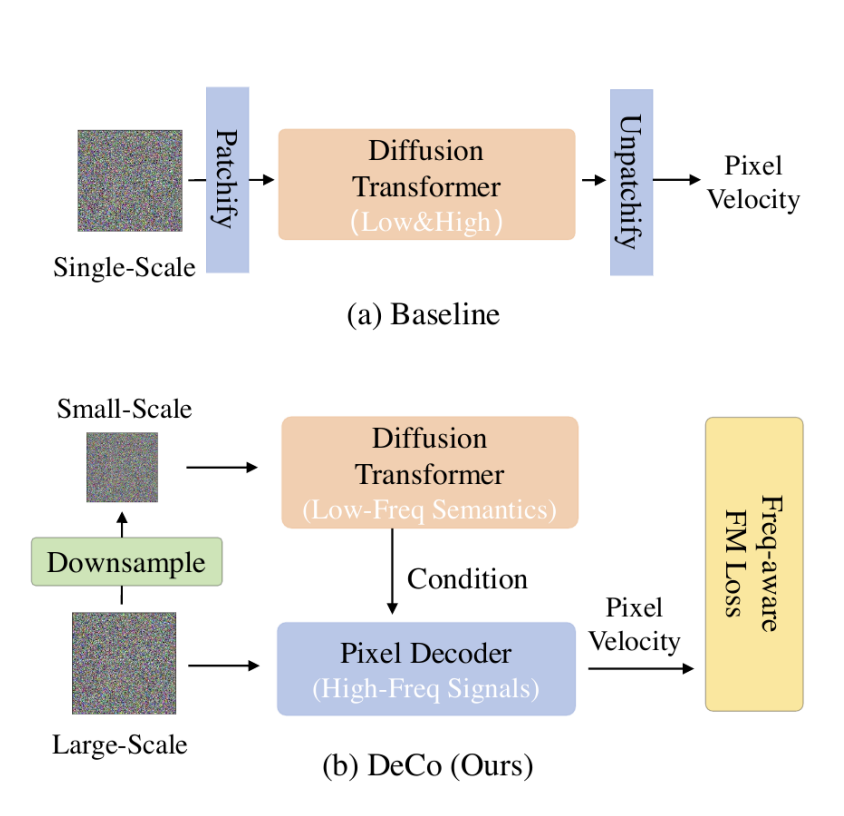
- 创新点一:引入较为轻量的pixel decoder,不包含attention计算,由N个 linear decoder blocks 和若⼲ linear projection layers 组成。所有操作都是局部且线性的,使其能够⾼效建模⾼频,⽽不引⼊ self-attention 的计算开销。使用AdaLN调制。
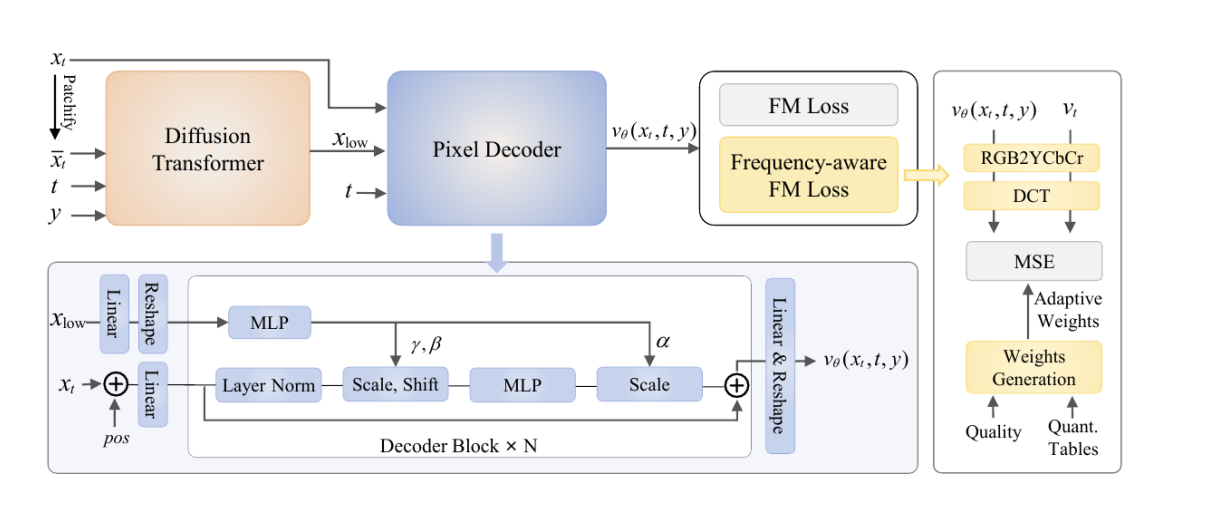
- 创新点二:引入Frequency-aware FM Loss,通过在FM loss上的不同区域加权,赋予感知上更重要的频率赋予更高权重。DeCo认为人眼对不同频率、亮度/色度的敏感程度不同。于是它把预测 velocity 和真实 velocity 做:1.RGB 转 YCbCr;2.8×8 block DCT;3.用 JPEG quantization table 的倒数作为权重;4.对感知上更重要的频率赋予更高权重。借用了 JPEG 中长期验证过的人类视觉系统先验
PixelGen: Improving Pixel Diffusion with Perceptual Supervision
1.这篇工作也比较简单,主要就是在JiT上加了两个感知损失。在pixel-diffusion系列模型中,JiT通过预测流形上的干净图像x缓解了高维噪声难以预测的问题。PixelGen认为,尽管 x-prediction 名义上约束输出位于 image manifold 上,pixel diffusion 仍然难以拟合它,pixel diffusion 需要强调 perceptually significant components 的 perceptual supervision,⽽不是均匀学习所有 pixels,uniform pixel-wise supervision 是低效的,它把容量花在 sensor noise 和 imperceptible details 等感知上不显著信号,对决定 visual quality 的 structures 强调有限。因此,PixelGen在JiT的FM loss的基础上,额外引入了两个perceptual loss:local LPIPS和global P-DINO supervision,并表明这两种损失是互补的。
2.由于LPIPS和DINO是在clean image层面的感知模型,因此JiT的x-pred性质使得它可以很自然的融入这两个感知损失。PixelGen还证明,当 $x_\theta$ 充分接近 clean image 时,这种 image-space supervision 最有用,因为 clean-image encoders 可能会 过度限制在高噪声阶段的预测。因此,作者引入一个简单 gate $g(t)$,仅在 low-noise regime 启用 perceptual losses。连同广泛使用的 REPA loss ,后者鼓励 生成模型的中间层表示 与预训练 DINOv2 encoder 对齐,最终 training objective 为:
其中Gate $g(t)$ 在 high-noise timesteps 禁用 perceptual losses。这种 end-to-end training 使 PixelGen 能够在没有 VAEs 的情况下更好拟合 real image manifold。
3.LPIPS loss:LPIPS 通过比较从冻结的预训练 VGG network $f_{\mathrm{VGG}}$ 提取的 multi-level feature activations 来衡量 perceptual similarity。LPIPS loss 可写为:
注意,这里是L2损失(的平方)。LPIPS 鼓励学习 perceptually important local patterns,⽽不是匹配精确 pixel values。
4.P-DINO loss: 仅靠 local patterns 不⾜以实现 high-fidelity generation。因此,引⼊ Perceptual DINO (P-DINO) loss,以提供 global semantic guidance。使用cosine similarity 对齐 predicted image $x_\theta$ 与 ground-truth image $x$:
P-DINO loss 通过对⻬ high-level representations 来提供 global semantic guidance,⿎励 predicted image 与整体 scene layout 和 object semantics ⼀致。
5.Noise gating:将perceptual loss均匀应⽤到所有 timesteps 可能有害。在高噪声时间步的预测图仍然模糊并缺乏 fine details,因此 clean-image feature matching 可能over-constrain early denoising。因此使⽤⼀个简单 timestep gate:在前30% high-noise timesteps 完全禁⽤ perceptual losses,并在后 70% low-noise timesteps 激活它们。实验表明, perceptual losses 在 prediction 进⼊相对 clean regime 后最有⽤。结合上述 LPIPS 和 P-DINO 分析,这⽀持 PixelGen 的核⼼设计,即在 low-noise timesteps 应⽤ perceptual supervision,并在其他位置依赖flow matching objective。