VOSR -- A Vision-Only Generative Model for Image Super-Resolution
原论文:https://arxiv.org/pdf/2604.03225
这篇工作是CVPR 2026的文章之一,提出的实现和结构不算太复杂,但是个人认为作者在这篇文章中对SR任务的本质及其与生成任务的区别分析的非常透彻,也与笔者的部分观念不谋而合。非常推荐仔细阅读一下原论文,相信能让你对SR有更深的理解。
引言
目前SOTA的SR模型,基本上都是从 generic T2I generator 出发,利用T2I 生成模型具备的大量真实图像先验来生成具备极佳细节的HR图像,这些方法通过prompt exacting,adapter等方法将LR转换为某种condition输入到T2I生成模型的DiT中。尽管有效,这些⽅法是适配 generic T2I generator 来处理 LR input,⽽不是直接为 detail generation 训练 restoration model,也就是说,不是原生SR模型(native SR model)。生成模型和SR模型一个本质的区别在于,生成模型是从一个毫无任何信息或与HR关联的纯noise分布开始,建模一个到HR分布的flow,而SR任务则完全不一样,LR分布本身实际上具备与HR分布的强关联,它们之间应该存在某种内在耦合联系,LR相对HR是位于较低维的空间中的,那么LR分布在某种意义上可以看作HR分布中的一张manifold或skeleton。T2I SR model能生成细节和感知极佳的SR图片,但对于 SR,仅仅 perceptually realistic 是不够的;restored details 还必须 faithful to the LR observation,T2I models 的 multi-modal pre-training 本质通过 text 或 text-aligned representations 引⼊ semantics,增加 detail hallucination ⻛险。即使这些 cues 源⾃ LR input 本身,它们仍然通过 text-conditioned generative path 注⼊,这⼀ path 往往着重于语义信息,而在空间解耦上是粗糙且与LR脱节的。
因此,VOSR试图提出⼀个纯 vision-based generative model,在不依赖 multimodal pre-training 的情况下直接为 restoration 训练,以媲美 T2I-based SR models的效果。这里的vision-only强调模型只用视觉数据来训练和提供条件,包括 synthesized LR-HR pairs 和来⾃vision encoders 的 auxiliary features,不使用文本-图像配对监督,不依赖文本语义路径,不使用文本-图像数据集或T2I预训练多模态模型。VOSR 不模仿 T2I training paradigm,⽽遵循真正的 native restoration-oriented design。
简单来讲,VOSR有以下三点贡献:
- 引⼊ vision semantic condition,它使⽤ DINO 等 pretrained vision encoders 直接从 LR image 的visual domain 提取语义丰富的 features。不同于 text-aligned semantics,这些 features 与 input 紧密grounded,更适合解决 fine-grained structural 和 texture ambiguities。
- 为 vision-only restoration problems 重新设计适配的 classifier-free guidance (CFG)。CFG技术常被用于T2I生成模型中,直接采⽤标准 fully unconditional auxiliary branch 对 SR来说是次优的:⼀旦 LR condition 被完全移除,auxiliary branch 必须从头学习 generic generation,⽽ conditional branch 则承担 input controllability。这种 role split 在 restoration 中难以优化,且学习不佳的 unconditional branch 会破坏 generation quality,同时为 restoration-oriented guidance 提供较弱 reference。因此,我们提出⼀种 restoration-oriented guidance,⽤ partially conditioned branch 替换 CFG 中的 unconditional branch。具体而言,保留 weak LR structural cues,同时丢弃 high-level semantics。这使 auxiliary branch 具有 generative 能力,⼜明确 anchored 到 input,使 resulting guidance direction restoration-oriented。因此,VOSR 强化 input-consistent restoration,⽽不是放⼤ generic generative preference。与T2I模型的CFG相反,较⼤的 guidance scales 通过将 predictions 推近 fully LR-conditioned branch 来偏向 fidelity,⽽较⼩ scales 允许通过偏向 partially conditioned branch 来获得更强 generation。
- ⾸先训练 multi-step VOSR model,然后将其蒸馏为 one-step variant ⽤于快速部署。结果表明,⼀个restoration-oriented、vision-only framework 可以在没有 multimodal pretraining 的情况下,同时提供强perceptual quality、practical efficiency 和低得多的 training cost。
“相关工作”的takeaways
- 使用l1 loss或pixel-wise objectives训练,可以实现强 distortion-based measures(例如 PSNR),但会导致过于平滑的细节,引入感知损失或对抗损失,则分别具有伪影和优化不稳定的问题。
- 纯vision-only SR方案天然与 restoration 对⻬,因为 generation 直接由 degraded input 驱动。然⽽,现有 vision-only generative SR methods 主要通过来⾃ LR input 的 structural cues 来 condition restoration,⽽没有显式引⼊ semantic guidance。在 severe degradation 下,这种 conditioning 通常不能提供⾜够 high-level information。换⾔之,vision-only SR 的限制不在于其 task formulation,⽽在于其缺乏⾜够强的 semantic abstraction 和 restoration-oriented guidance。
- T2I SR方案受益于从 massive image-text corpora 中学习到的强priors,并经常实现令⼈印象深刻的 perceptual quality。典型设计通过 prompts、ControlNet-like branches、adapters 或 text-aligned features 注⼊ LR information。这些方法不够native to SR,不是直接训练 restoration model,⽽是约束 generic image generator 符合 LR image。虽然它们在利⽤ pre-trained image priors ⽅面⾮常有效,但在 generic image generation 与 faithful restoration 之间引⼊ structural tension。此外,这些⽅法使⽤的 semantic cues 通常表示在 text 或 text-aligned spaces 中,它们与 pixel-level image details 对⻬时 spatially coarse。另外,这⼀范式继承了 multimodal foundation models 的⾼ training 和deployment cost。
- ⼀⽅⾯,vision-only SR 天然 grounded in degraded input,并更好对⻬ restoration objective,但其generative capability 受 severe degradation 下 weak semantic abstraction 限制。另⼀⽅面,T2I-based SR 提供强 image priors,但其 generic multimodal generation framework 并⾮ restoration-native,且经常受pretrained backbone model size 约束,使 lightweight、budget-aware restoration design 具有挑战性。能否训练⼀个 generative SR model,使其在保持完全 grounded in input LR image 的同时,直接在 visual domain 中引⼊更强 semantics?这种generative SR 理想上应同时⽀持 high perceptual quality 和 efficient inference。VOSR就是在这样的背景下开发出的框架。
方法
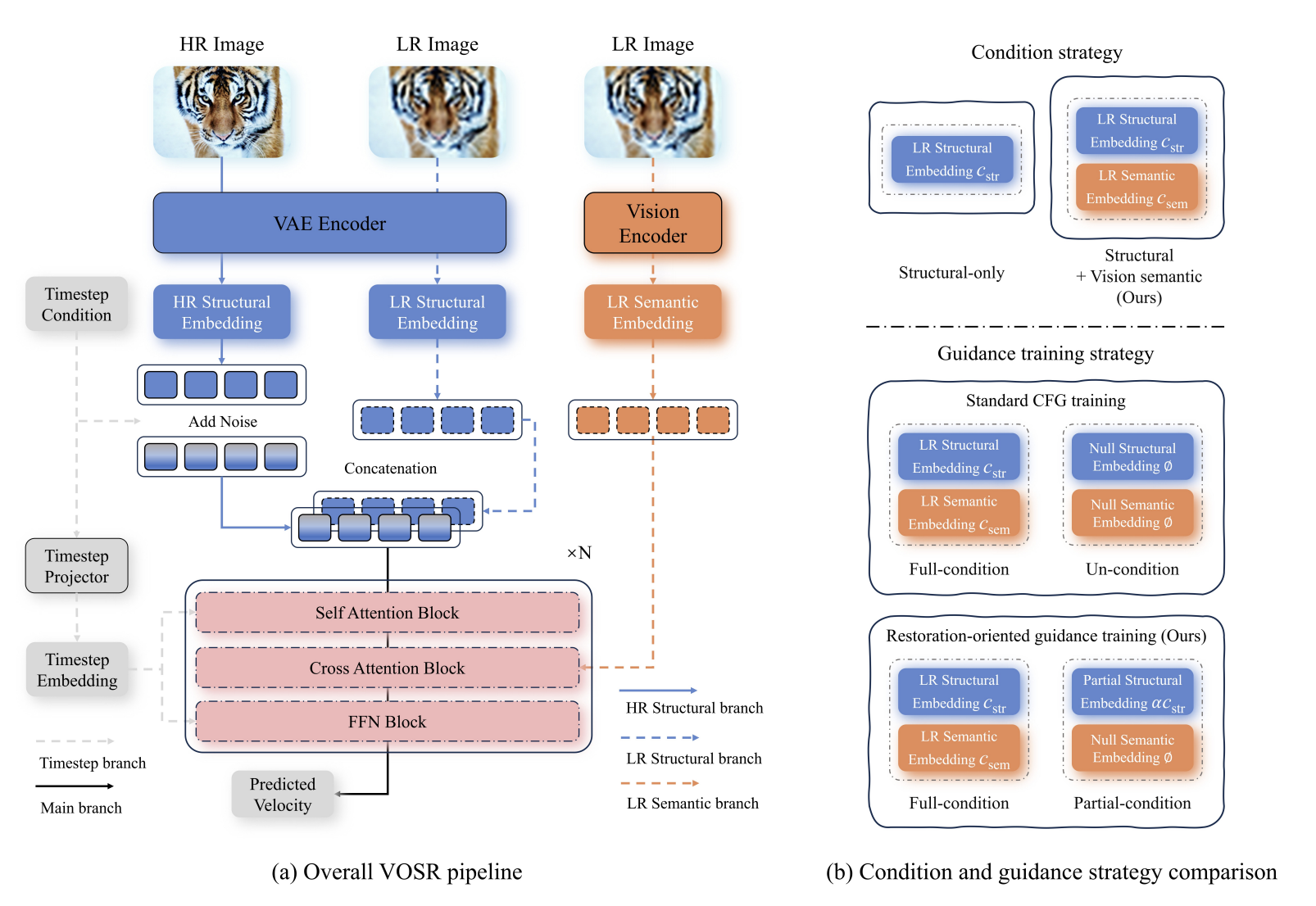
如图,依然使用multi-steps v-pred latent DiT架构。在进入DiT前,将noisy HR latent与LR latent在channel维concat作为DiT输入,这一操作是LR的structural embedding,通过concat,LR的结构信息被强绑定在模型中。同时,将LR经过vision encoder提取出的semantic feature map通过cross attention而不是AdaLN的方式注入到DiT中,与一般的AdaLN conditioning相比,这是一种更直接,更强的注入方式。该semantic conditioning在partially conditioned branch中不使用,而在fully conditioned branch中使用,从而形成了一种专门适配SR任务的CFG设计。
框架
SR 的⽬标是恢复⼀个 perceptually realistic 且 faithful to the input 的 high-resolution image 。不同于 text-to-image generation,SR 是 purely vision-conditioned。
Vision Semantic Condition
low-level structural conditioning 和 high-level visual semantic guidance:将 LR image 编码到同⼀个 latent space 中,作为 spatially aligned structural condition 来保留 content 和 layout,并从 pretrained vision encoder 提取 semantic features 作为 visual semantic guidance,为 detail generation 提供语义丰富且空间 grounded 的 cues。
现有 vision-only generative SR models 主要依赖来自 LR input 的 structural cues。然而,在 severe degradation 下,structural conditioning 单独可能不足,因为 LR observation 允许多个 plausible HR reconstructions,导致 semantic ambiguity。因此,VOSR 采用 two-branch conditioning design,结合 LR structure 与 semantic information。
具体而言,structural branch 使用与将 HR images 映射到 latent space 相同的 VAE encoder $\mathcal{E}$ 对 LR image 进行编码,产生 structural condition $c_{\mathrm{str}} = \mathcal{E}(I_{\mathrm{LR}})$ 以保持 spatial content。并行地,pretrained vision encoder $\mathcal{V}$,例如 DINO,提取 semantic condition $c_{\mathrm{sem}} = \mathcal{V}(I_{\mathrm{LR}})$。不同于 text 或 text-aligned representations,$c_{\mathrm{sem}}$ 完全在 visual domain 中提取,更适合 fine-grained restoration。我们的 denoising backbone 是 diffusion transformer,它以 noisy HR latent $z_t$ 和 timestep embedding 作为输入。Structural condition $c_{\mathrm{str}}$ 作为 spatially aligned latent conditioning 被注入,而 semantic condition $c_{\mathrm{sem}}$ 通过 cross-attention 引入以提供 high-level context。以这种方式,structural features 保持 spatial fidelity,而 semantic features 在 detail synthesis 期间解决 ambiguity。该设计完全在 visual domain 内引入 high-level semantics,避免 SR 中的 text 或 text-aligned conditioning。
Restoration-Oriented Guidance
对于 restoration,auxiliary guidance branch 的设计尤其重要,因为 SR 不是 text-conditioned generation,⽽是 input-anchored generation。
先前的CFG形如 $v_{\mathrm{cfg}} = v_{\mathrm{uncond}} + s(v_{\mathrm{cond}} - v_{\mathrm{uncond}})$,其中 $v_{\mathrm{cond}}$ 和 $v_{\mathrm{uncond}}$ 分别表示 conditional 和 unconditional predictions,$s$ 是 guidance scale。该 formulation 在 T2I generation 中非常有效,其中 unconditional branch 为无 text control 的 generic image generation 提供自然 reference。然而,对于从头训练的 SR,这种 fully unconditional branch 并不那么合适。一旦 LR input 被完全移除,auxiliary branch 必须学习 generic image generation,而 conditional branch 单独负责保持 input fidelity。这种角色分离使 image restoration 难以优化,并且 weak unconditional learning 可能提供较差 guidance reference。
基于这一观察,我们用 partially conditioned branch 替换 unconditional branch。目标并不是任意丢弃 conditions,而是构建一个与 fully conditioned branch 不同且定义有意义 restoration-oriented guidance direction 的 auxiliary branch。具体而言,我们不移除所有 conditions,而是在丢弃 semantic guidance 的同时保留 weakened LR structural cues。与同时使用 structural 和 semantic conditions ($c_{\mathrm{str}}, c_{\mathrm{sem}}$) 的 fully conditioned branch 相比,partially conditioned branch 只保留 scaled structural condition 并移除 semantic conditioning。令 $\alpha \in (0, 1)$ 表示 structural retention factor。两个 branches 定义为:$v_{\mathrm{cond}} = v_\theta(z_t, t, c_{\mathrm{str}}, c_{\mathrm{sem}})$ 和 $v_{\mathrm{pcond}} = v_\theta(z_t, t, \alpha c_{\mathrm{str}}, \varnothing)$ ,其中 $\varnothing$ 表示 semantic conditioning 缺失。这样,两个 branches 都保持 anchored to LR input,而它们的差异捕获 stronger structure 和 semantic guidance 的影响。训练期间,我们随机采样 fully conditioned mode 或 partially conditioned mode,使 shared model 在 unified objective 下学习两种 behaviors。遵循 velocity parameterization 中的 standard latent diffusion training,multi-step objective 为:
其中 $v_t = z_1 - z_0$ 是 ground-truth velocity target,$\kappa$ 表示 sampled conditioning mode,即 fully conditioned branch ($c_{\mathrm{str}}, c_{\mathrm{sem}}$) 或 partially conditioned branch ($\alpha c_{\mathrm{str}}, \varnothing$)。
测试时,我们应用 restoration-oriented guidance:
其中 $s$ 是 guidance scale。不同于 standard CFG,这里的 auxiliary branch 仍然 weakly conditioned on LR input。因此,guidance direction 并不是从 unconditional generation 移向 conditioned restoration;相反,它从 weakly anchored branch 移向 strongly anchored one。随着 $s$ 增加,prediction 被驱动得更接近 fully conditioned branch,从而强化 input consistency。随着 $s$ 减小,prediction 偏向 partially conditioned branch,其中 semantic conditioning 被移除且 structural conditioning 被削弱,从而允许更大的 plausible detail generation 空间。该行为与 T2I-based SR中常用 CFG 显著不同,后者可写为:
其中 LR control 由两个 branches 共享。Guidance direction 主要反映额外 semantic priors 的注入,并且增大 guidance scale 通常会放大 generative semantics。相反,在我们的 formulation 中,$s = 0$ 恢复 partially conditioned branch,$s = 1$ 恢复 fully conditioned branch。因此,较小 $s$ 倾向于产生更 generative 的结果,而较大 $s$ 偏向对 LR input 更好的 fidelity。这使我们的 VOSR restoration-oriented,在 input-anchored restoration space 中平衡 generation 和 fidelity。
⽤于⾼效推理的 One-Step Distillation
distillation 只改变 sampling efficiency,⽽不改变 restoration formulation。经验上,recursive-consistency-based variant 对 SR 表现最佳,在 perceptual quality 与 structural fidelity 之间提供更好平衡。因此,我们在主要实验中采⽤该 variant。以这种⽅式,VOSR 在实现 efficient one-step inference 的同时,保留与 multi-step teacher 相同的 restoration-oriented formulation。
实验
使⽤ Real-ESRGAN degradation pipeline 合成 LR-HR training pairs。VOSR 仅在 synthetic pairs 上训练,但在 synthetic 和real-world test sets 上评估,以评估 generalization。
总体⽽⾔,T2I-based methods 经常产⽣ visually sharp results,但在恢复需要 faithful to the LR input 的 fine structures 时不够可靠。相⽐之下,VOSR 持续恢复更多 local details,结构更清晰且hallucinations 更少
结论
VOSR重新审视SR任务的本质,通过SR native的设计,在 perceptual quality、faithfulness 和 efficiency 上取得强性能,并且VOSR 的 training expenses 低得多,并⽀持 one-step inference,验证了 vision-only generative modeling 是 real-world SR 中 T2I adaptation 的强替代⽅案。